看过来,RK3576 NPU方案你用对了吗?
本文基于Mil MYD-LR3576开发板,详细记录了如何使用5兆USB摄像头实现640640分辨率YOLO5s目标检测并将结果实时输出到1080P屏幕的整个过程。通过系统级软硬件协同优化,最终将端到端延迟控制在40ms以内,实现了20FPS的稳定实时检测性能。文章重点从相机特性、显示通道选择、RGA硬件加速、RKNN NPU集成等关键技术方面进行分析,为嵌入式AI视觉系统的开发和优化提供一整套的思路和实用的解决方案。
PART 01系统架构与性能目标1.1 硬件平台主控芯片:瑞芯微RK3576(四核A72+四核A53,6TOPS NPU、RGA、GPU、VPU)摄像头:500万像素USB摄像头(支持MJPEG/YUYV格式)显示器:4K HDMI 显示(通过Weston 桌面环境显示)开发板:Mil MYD-LR3576 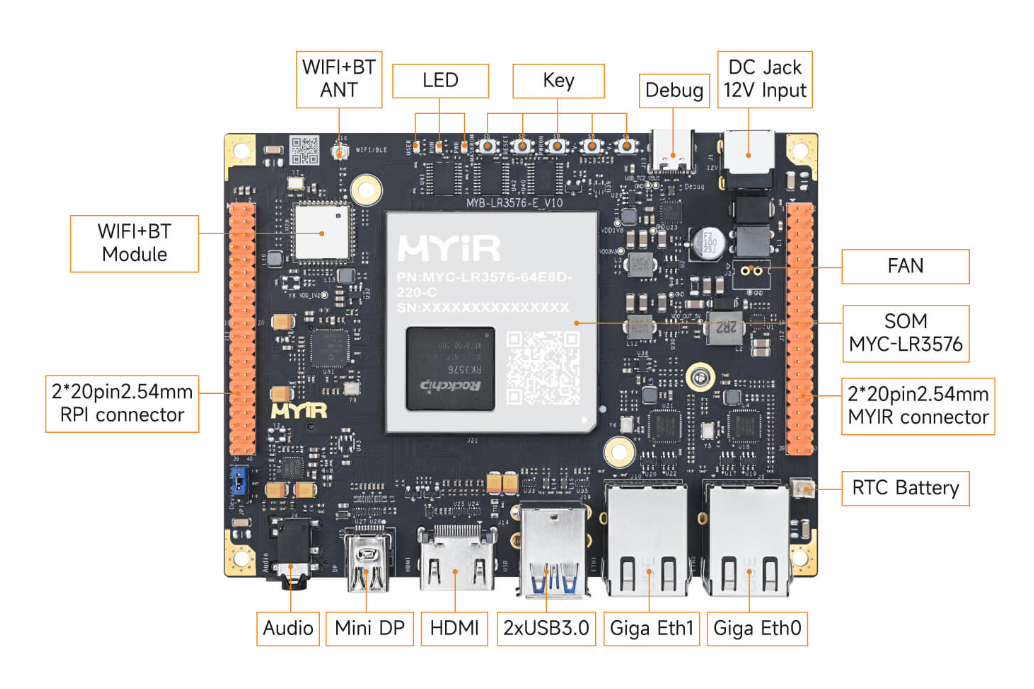 Mil RK3576 核心板开发板1.2 软件平台使用Mil 官方V2.0.0 SDK 提供的buildroot 镜像,内核版本为6.1.118。系统信息如下:
Mil RK3576 核心板开发板1.2 软件平台使用Mil 官方V2.0.0 SDK 提供的buildroot 镜像,内核版本为6.1.118。系统信息如下:
root@myd-lr3576-buildroot:/# uname -aLinuxmyd-lr3576-buildroot6.1.118#1SMP 星期五九月2602:34:15UTC2025aarch64 GNU/Linux
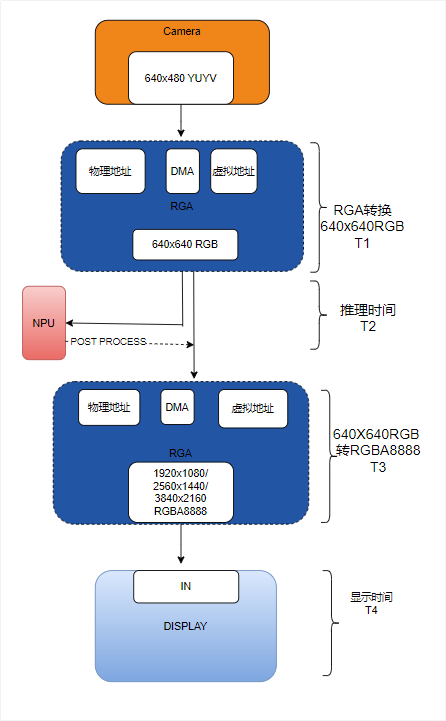
1.3 性能目标实时性:完成从相机采集NPU推理屏幕显示的完整流程,不超过相机一帧。输入/输出:尽可能提高相机采集帧率,并在显示端支持更高的输出分辨率。功能:实现YOLO5的目标检测,并在视频屏幕中实时绘制检测框。PART 02数据处理流程与优化实践摄像头数据需要经过哪些流程才能输出到显示器上?参考下图。
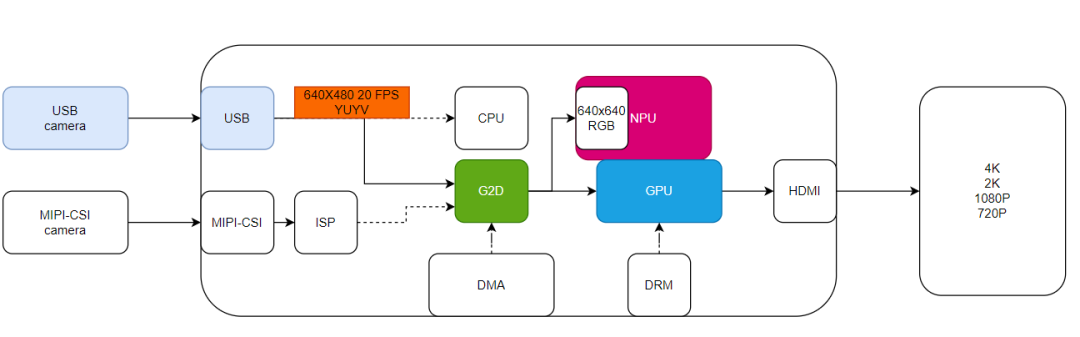
2.1 CPU处理方案及其瓶颈 如果摄像机数据直接显示在屏幕上,首先了解它们的输入和输出关系。可以使用v4l2-ctl -D -d /dev/videoxx --list-formats-ext 查看摄像头输出使用cat /sys/kernel/debug/dri/0/state 显示输出
如果摄像机数据直接显示在屏幕上,首先了解它们的输入和输出关系。可以使用v4l2-ctl -D -d /dev/videoxx --list-formats-ext 查看摄像头输出使用cat /sys/kernel/debug/dri/0/state 显示输出
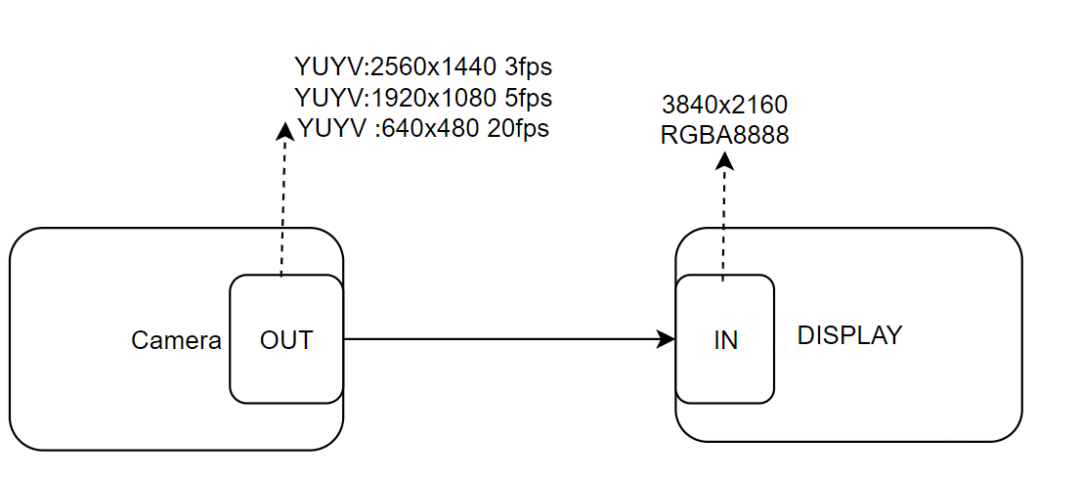 基于实时性能,需要选择输出对应的最高fps分辨率。这里选择640x480 20fps,那么需要将YUYV格式替换为RGBA8888才可以显示。显示尺寸不超过最大屏幕分辨率3840x2160。 CPU处理过程如下
基于实时性能,需要选择输出对应的最高fps分辨率。这里选择640x480 20fps,那么需要将YUYV格式替换为RGBA8888才可以显示。显示尺寸不超过最大屏幕分辨率3840x2160。 CPU处理过程如下
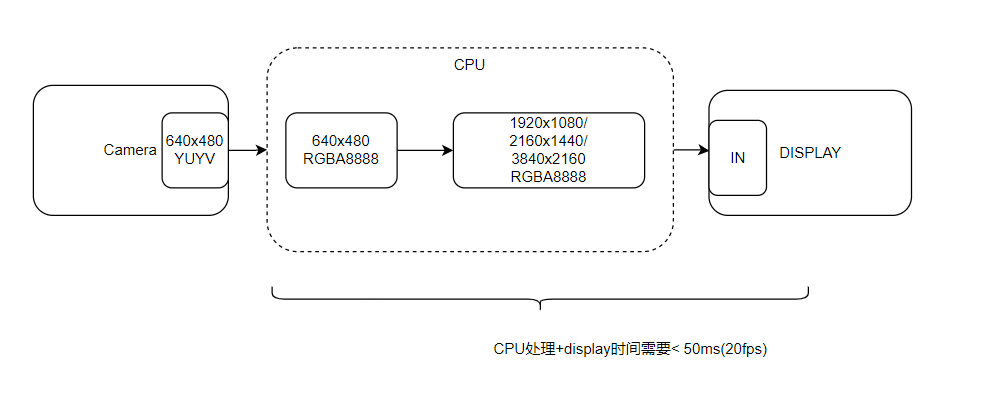 如果要将相机采集到的YUYV格式数据直接显示在屏幕上,需要先将其转换为RGBA8888格式。格式转换和缩放在CPU上的表现如下(输入为640480 YUYV):
如果要将相机采集到的YUYV格式数据直接显示在屏幕上,需要先将其转换为RGBA8888格式。格式转换和缩放在CPU上的表现如下(输入为640480 YUYV):
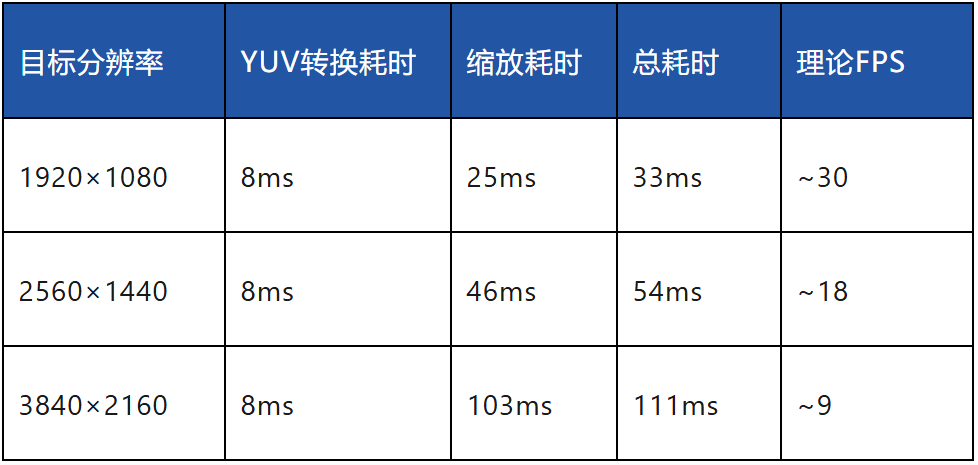 可以看出CPU在处理1080P分辨率时已接近能力上限,更高分辨率无法满足实时要求。2.2 引入RGA进行硬件加速RGA是RK3576 2D处理芯片模块。其功能是对图像进行旋转、缩放、旋转、镜像和格式化。根据手册信息,它能处理的数据表现为物理地址DMA虚拟地址。然后用RGA来代替CPU的格式转换和缩放。
可以看出CPU在处理1080P分辨率时已接近能力上限,更高分辨率无法满足实时要求。2.2 引入RGA进行硬件加速RGA是RK3576 2D处理芯片模块。其功能是对图像进行旋转、缩放、旋转、镜像和格式化。根据手册信息,它能处理的数据表现为物理地址DMA虚拟地址。然后用RGA来代替CPU的格式转换和缩放。
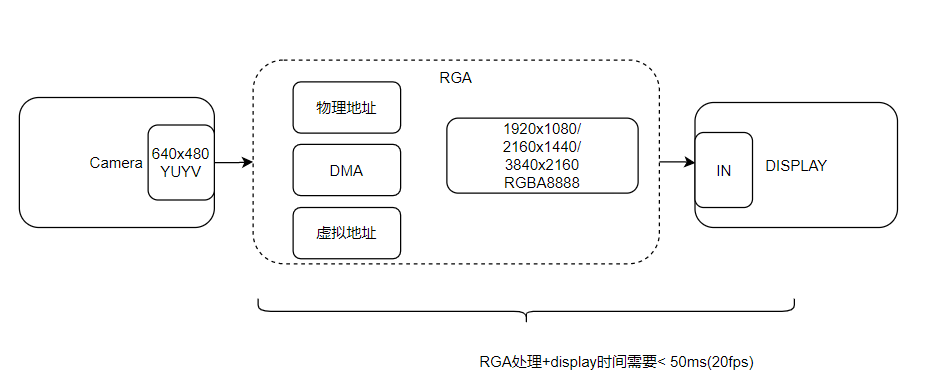 RGA 一次性执行转换和缩放。下面是CPU运行情况的对比图。使用RGA代替CPU进行格式转换和缩放后,性能对比如下:
RGA 一次性执行转换和缩放。下面是CPU运行情况的对比图。使用RGA代替CPU进行格式转换和缩放后,性能对比如下:
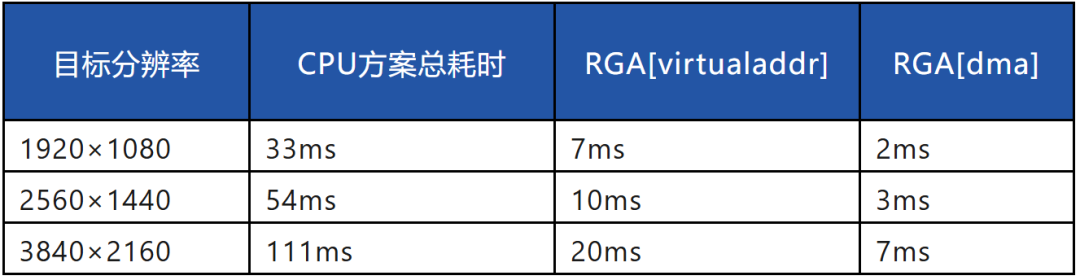 RGA的推出带来了数量级的性能提升,尤其是DMA模式,大大降低了处理延迟。2.3 GPU直接显示方案OpenCV的imshow在调试阶段经常使用来显示图像,但它依赖CPU参与,无法满足实时要求。系统实际使用的是DRM显示框架和Weston桌面环境,因此我们选择Wayland-client方案进行直接显示,实现GPU直接显示。
RGA的推出带来了数量级的性能提升,尤其是DMA模式,大大降低了处理延迟。2.3 GPU直接显示方案OpenCV的imshow在调试阶段经常使用来显示图像,但它依赖CPU参与,无法满足实时要求。系统实际使用的是DRM显示框架和Weston桌面环境,因此我们选择Wayland-client方案进行直接显示,实现GPU直接显示。
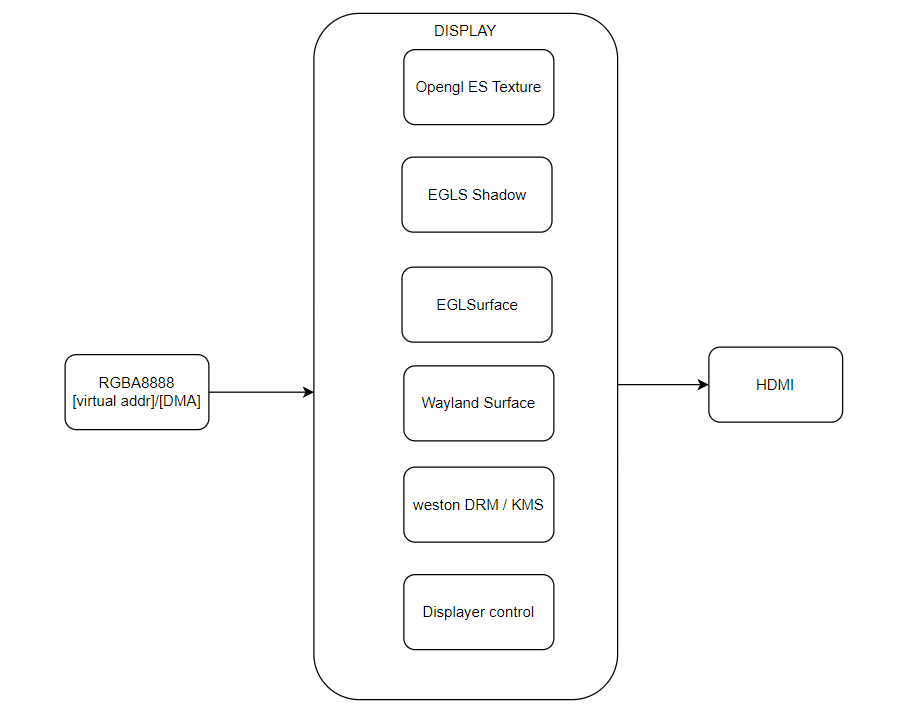
不同输入方式下显示时间消耗对比:
 2.4 NPU推理流程与耗时分析
2.4 NPU推理流程与耗时分析 通用模型,通过rknn-toolkit2转换为rknn后,可以通过RKNN API调用推导。使用rknn_model_zoo yolo5模型转换生成模型,yolov5s-640-640.rknn和coco80labels_list.txt,以及一些调用参考代码。其输入必须为640x640RGB 格式。rknn推理虚拟地址关键步骤如下:
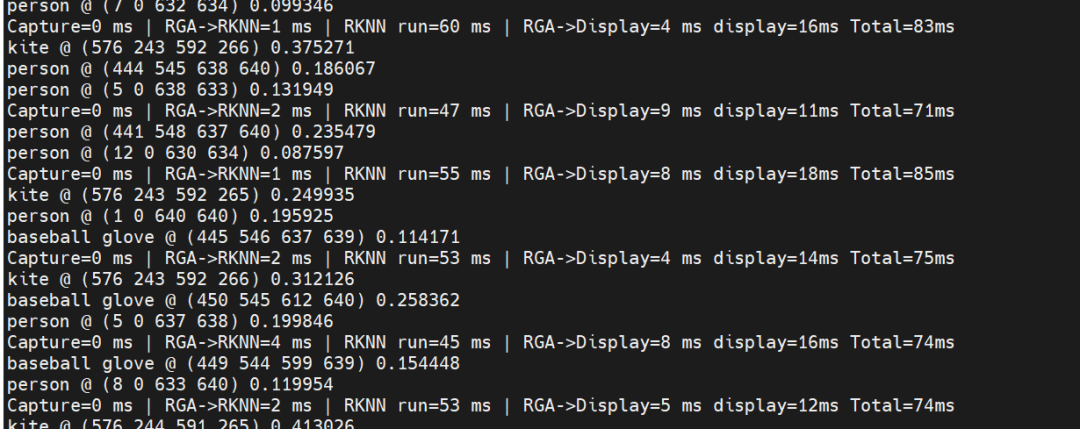
通用模型,通过rknn-toolkit2转换为rknn后,可以通过RKNN API调用推导。使用rknn_model_zoo yolo5模型转换生成模型,yolov5s-640-640.rknn和coco80labels_list.txt,以及一些调用参考代码。其输入必须为640x640RGB 格式。rknn推理虚拟地址关键步骤如下: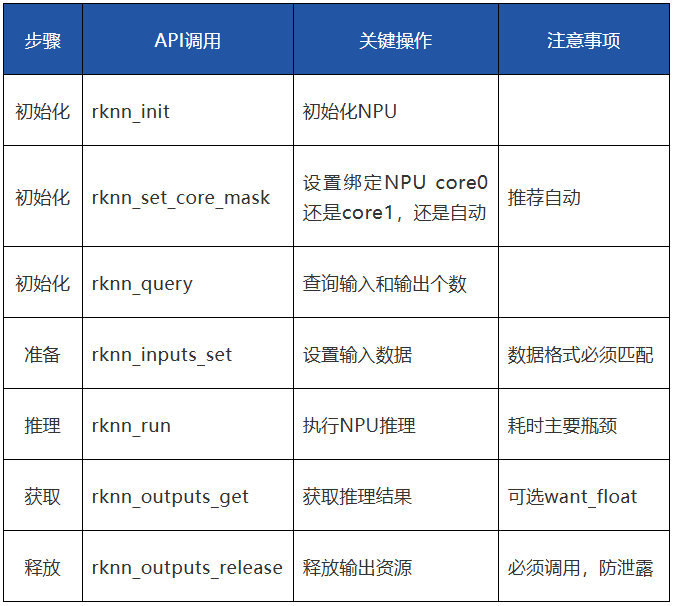 经过实际测试,rknn_run 这一阶段大约需要26~31ms。 rknnoutputsget获得数据后,可以在内部进行处理,检测目标、坐标、置信度指数,并根据实际需要绘制在屏幕上。该步骤可以由多个进程异步处理,不计入串行时间。笔者测试大概会多花8ms左右。
经过实际测试,rknn_run 这一阶段大约需要26~31ms。 rknnoutputsget获得数据后,可以在内部进行处理,检测目标、坐标、置信度指数,并根据实际需要绘制在屏幕上。该步骤可以由多个进程异步处理,不计入串行时间。笔者测试大概会多花8ms左右。
 那么我们来看看从相机实时采集NPU推理到展示整个过程的耗时过程。
那么我们来看看从相机实时采集NPU推理到展示整个过程的耗时过程。
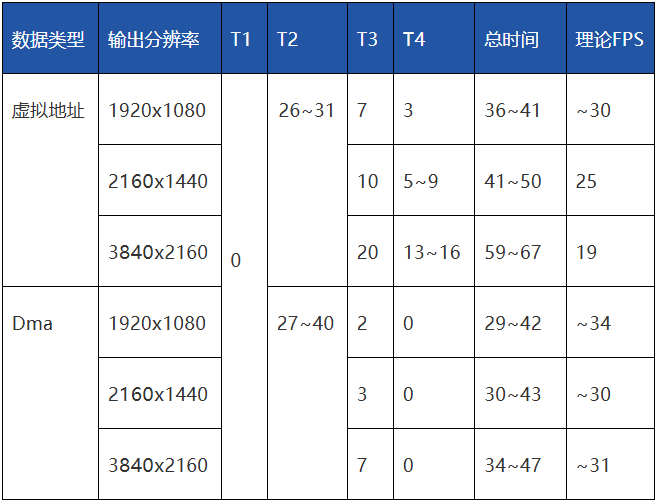 结论:NPU推理阶段(T2)仍然是系统主要耗时的部分。但通过DMA+RGA+直接显示的优化组合,系统整体延迟大幅降低,在高分辨率输出下仍能保持稳定的帧率。
结论:NPU推理阶段(T2)仍然是系统主要耗时的部分。但通过DMA+RGA+直接显示的优化组合,系统整体延迟大幅降低,在高分辨率输出下仍能保持稳定的帧率。
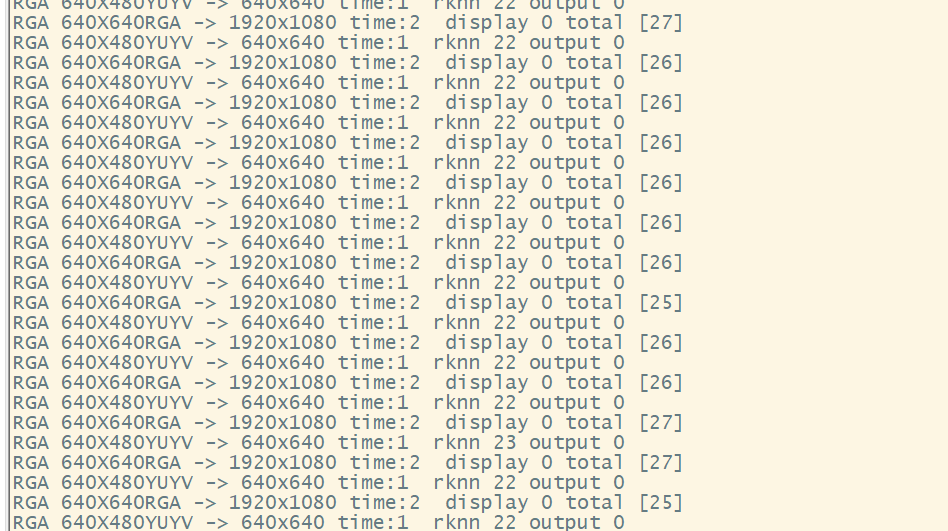
2.5 多摄像头系统资源占用分析虚拟内存解决方案1个摄像头


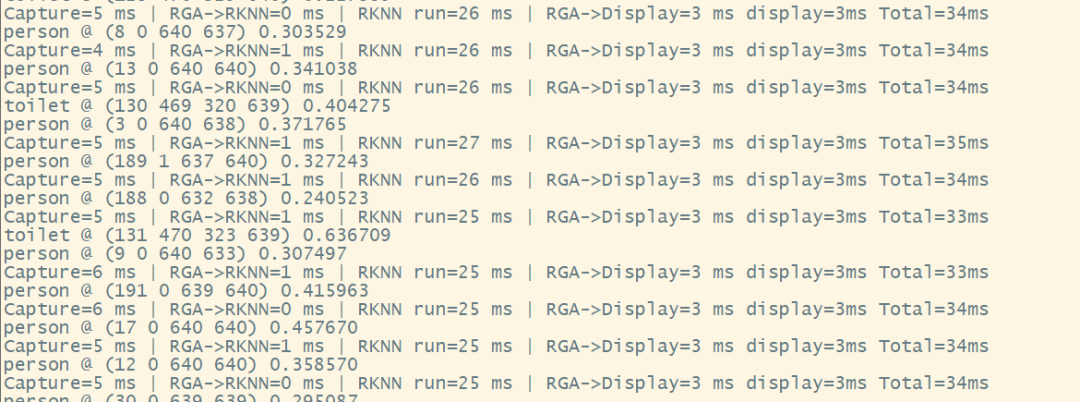 4 相机
4 相机
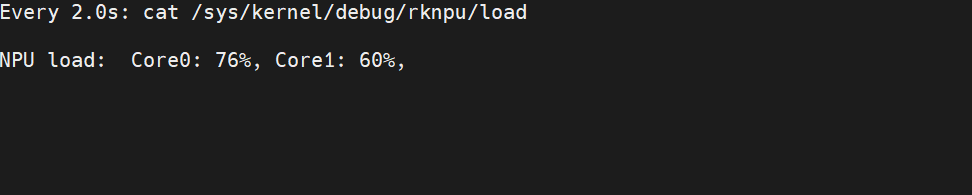
DMA方案1相机输出
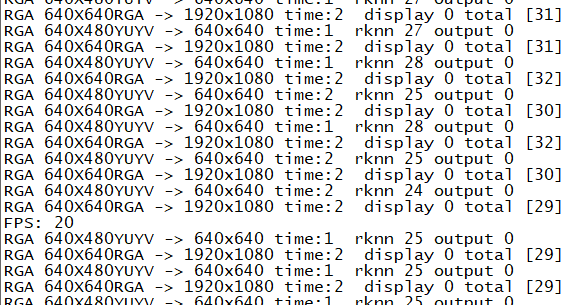
 2 摄像头输入
2 摄像头输入
 PART 03总结在嵌入式AI视觉系统中,NPU的算力是决定性能上限的关键因素。然而,要达到这个上限,必须建立高效的数据管道。本文的实践表明,通过RGA硬件加速、DMA零拷贝数据传输和GPU直接显示的协同优化,可以完全释放RK3576平台的异构计算潜力,端到端延迟可以控制在几十毫秒以内,实现高清、实时的目标检测应用。这种优化思路也适用于其他具有类似硬件加速单元的嵌入式AI平台。
PART 03总结在嵌入式AI视觉系统中,NPU的算力是决定性能上限的关键因素。然而,要达到这个上限,必须建立高效的数据管道。本文的实践表明,通过RGA硬件加速、DMA零拷贝数据传输和GPU直接显示的协同优化,可以完全释放RK3576平台的异构计算潜力,端到端延迟可以控制在几十毫秒以内,实现高清、实时的目标检测应用。这种优化思路也适用于其他具有类似硬件加速单元的嵌入式AI平台。