深入解析NVIDIA Nemotron 3系列开放模型
这个新的开放模型系列引入了开放式混合Mamba-Transformer MoE 架构,可在多智能体系统中实现快速长上下文推理。
基于代理的人工智能系统越来越依赖于一组协作运行的代理,包括检索器、规划器、工具执行器、验证器等,它们需要在大规模环境下长期协同工作。此类系统需要能够提供快速吞吐量、高推理精度以及跨大规模输入的一致一致性的模型。它们还需要一定程度的开放性,使开发人员能够在任何运行环境中定制、扩展和部署模型。
NVIDIA Nemotron 3 系列开放模型(Nano、Super、Ultra)、数据集和技术专为在新时代构建专业的基于代理的AI 而设计。
该系列介绍了异构Mamba-Transformer混合专家(MoE)架构、交互式环境强化学习(RL)和原生100万个令牌上下文窗口,可以为多智能体应用程序提供高吞吐量和长期推理能力。
Nemotron3的新功能
Nemotron3引入了多项创新技术来准确满足基于代理的系统的需求:
混合Mamba-TransformerMoE 主干网提供出色的测试时间效率和远程推理能力。
围绕现实世界的类似代理任务设计的多环境强化学习。
100万个token上下文长度支持深度多文档推理和长期代理记忆。
开放透明的训练管道,包括数据、权重和解决方案。
Nemotron3 Nano 现已上市,并附带即用型指南。 Super和Ultra将在稍后发布。
简单提示示例
Nemotron3模型核心技术
混合Mamba-TransformerMoE 架构
Nemotron3 将三种架构集成到一个主干中:
Mamba层:实现高效的序列建模
Transformer层:保证推理精度
MoE路由:实现可扩展的计算效率
Mamba 层擅长以极低的内存开销跟踪长程依赖,即使在处理数十万个token 时也能保持稳定的性能。 Transformer 层通过细粒度的注意力机制对此进行了补充,该机制捕获代码操作、数学推理或复杂规划等任务所需的结构和逻辑关联。
MoE 组件增加了有效参数的数量,而不会增加密集的计算开销。每个令牌仅激活一部分专家,从而减少延迟并提高吞吐量。这种架构特别适合需要同时运行大量轻量级代理的集群场景,每个代理都生成计划、检查上下文或执行基于工具的工作流。
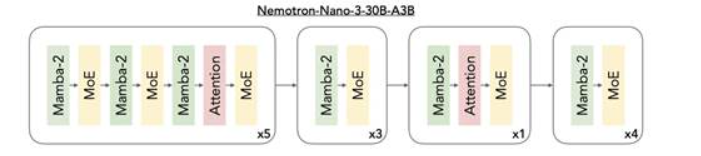
图1:Nelotron3 混合架构。该模型通过交错部署Mamba-2 和MoE 层并辅以少量自注意力层,实现了最大推理吞吐量,同时保持领先的准确性。
多环境强化学习(RL)训练
为了使Nemotron3 适应真正的类似代理的行为,该模型通过NeMoGym 中多个环境的强化学习进行了后训练,NeMoGym 是一个用于构建和扩展RL 环境的开源库。这些环境评估模型执行连续操作序列(而不仅仅是单个响应)的能力,例如生成正确的工具调用、编写功能代码或生成满足可验证标准的多步骤计划。
这种基于轨迹的强化学习产生的模型可以在多步骤工作流程中稳定执行,减少推理漂移,并处理基于代理的管道中常见的结构化操作。由于NeMoGym 是开源的,因此开发人员在为特定领域的任务定制模型时可以重用、扩展甚至创建自己的环境。
这些环境和强化学习数据集与NeMoGym 一起在线提供,供有兴趣使用这些环境训练自己的模型的用户使用。
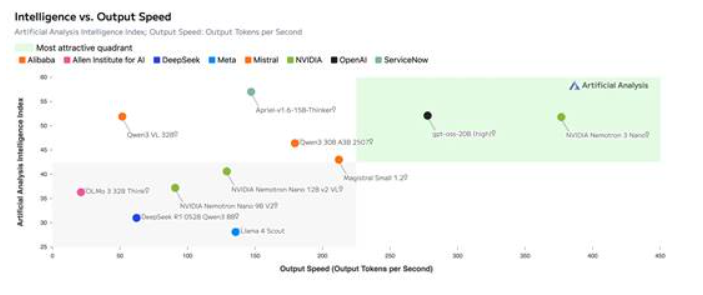
图2:Nemotron3 Nano 通过混合MoE 架构实现极高的吞吐效率,并通过NeMoGym 先进的强化学习技术实现领先的准确性
100 万个令牌上下文长度
Nemotron3 的100 万个令牌上下文可实现跨大型代码库、长文档、扩展对话和聚合搜索内容的连续推理。代理不需要依赖碎片化的分块启发法,并且可以在单个上下文窗口中保留完整的证据集、历史缓冲区和多阶段计划。
这个长上下文窗口受益于Nemotron3 的混合Mamba-Transformer 架构,该架构可以有效地处理超大规模的序列。 MoE 路由还可以保持单个令牌的计算成本较低,从而可以在推理过程中处理这些大型序列。
对于企业级搜索增强生成、合规性分析、多小时代理会话或整体存储库理解等场景,100 万个令牌窗口可以显着强化事实基础并减少上下文碎片。
Nemotron3 Super和Ultra核心技术
潜在的教育部
Nemotron3 Super 和Ultra 引入了潜在MoE,专家首先在共享潜在表示中进行操作,然后将输出投影回代币空间。这种方法使模型能够以相同的推理成本调用多达4 倍的专家,从而可以更好地围绕微妙的语义结构、领域抽象或多跳推理模式进行专业化。
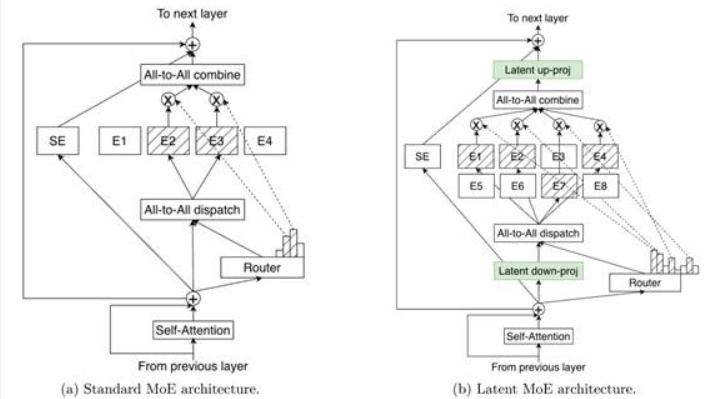
图3:标准MoE 和潜在MoE 架构的比较。在潜在的MoE 中,代币被投射到更小的潜在维度,用于专家路由和计算,这降低了通信成本,同时支持更多专家的参与并提高每字节的准确性。
多标记预测(MTP)
MTP 使模型能够在一次前向传递中预测多个未来令牌,从而显着提高长推理序列和结构化输出的吞吐量。对于规划、轨迹生成、扩展思维链或代码生成,MTP 可以减少延迟并提高代理响应能力。
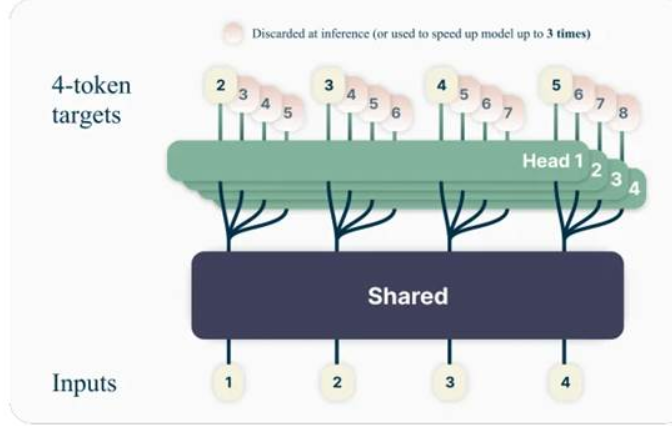
图4:多令牌预测(来自论文《通过多token预测实现更优更快的大语言模型》)可以同时预测多个未来令牌,在训练阶段将准确率提高约2.4%,并在推理阶段实现推测解码加速。
NVFP4 培训
Super 和Ultra 模型均以NVFP4 精度进行预训练。 NVIDIA 的4 位浮点格式为训练和推理提供了业界领先的成本准确率。我们为Nemotron3 设计了更新版本的NVFP4 解决方案,以确保在25 万亿代币预训练数据集上进行准确稳定的预训练。预训练过程中的大部分浮点乘法和加法运算都使用NVFP4格式。
持续致力于开放模式
Nemotron3 体现了NVIDIA 对透明度和开发人员授权的承诺。该模型的权重已根据NVIDIA 开放模型许可证公开发布。 NVIDIA 的合成预训练语料库(近10 万亿个代币)可以查阅或重复使用。开发人员还可以在Nemotron GitHub 存储库中获取详细的培训和培训后解决方案,以实现完整的再现性和定制化。
Nemotron3 Nano 已发布,为高吞吐量、长上下文代理系统奠定了基础。 Super和Ultra将于2026年上半年发布,并将在此基础上进一步深化推理能力,提高架构效率。
Nemotron3 Nano 现已发布
该系列的第一款型号Nemotron3 Nano 已于近期发布。该模型总参数为300 亿,激活参数为30 亿,专为DGX Spark、Hopper GPU 和Blackwell GPU 设计,允许用户使用Nemotron3 系列中更高效的模型进行开发。
如果您想了解更多有关Nemotron3 Nano 的技术细节,可以访问Hugging Face 博客或阅读技术报告。
该模型实现了极高的吞吐效率,在人工分析智能指数中领先,并在人工分析开放性指数上与NVIDIA Nemotron Nano V2 保持相同的分数。这充分展示了其在多智能体任务中的效率,同时是透明的和可定制的。
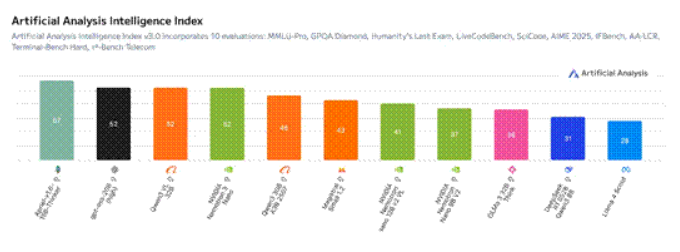
图5:在人工分析智能指数v3.0 上,Nemotron3 Nano 的准确度(52)领先于同尺寸的模型。
开发人员现在可以在各种部署和开发工作流程中使用Nemotron3 Nano:
通过NVIDIA 使用指南启动模型
我们为几种主要推理引擎提供即用型指南:
vLLM 使用指南:部署具有高吞吐量连续批处理和流输出的Nemotron3 Nano。
SGLang 使用指南:运行针对多代理工具调用工作负载而优化的快速、轻量级推理。
TRT LLM 使用指南:部署针对低延迟生产级环境全面优化的TensorRTLLM 引擎。
每套用户指南均包含配置模板、性能优化建议和参考脚本,可帮助您在几分钟内启动Nemotron3 Nano。
此外,您可以立即在任何NVIDIA GPU 上使用Nemotron,从GeForce RTX 台式机/笔记本电脑、RTX Pro 工作站到DGX Spark,并开始使用Llama.cpp、LM Studio 和Unsloth 等顶级框架和工具。
使用Nemotron 开放训练数据集进行开发
NVIDIA 还发布了整个模型开发过程中使用的开放数据集,为构建高性能、值得信赖的模型带来了前所未有的透明度。
新数据集的特点包括:
Nemotron 预训练:新的3 万亿token 数据集通过合成增强和注释管道进行增强,更全面地覆盖代码、数学和推理场景。
Nemotron Post-Training 3.0:1300万个样本语料用于监督微调和强化学习,支持Nemotron3 Nano的对齐和推理能力。
Nemotron 强化学习数据集:精选的强化学习数据集和环境的集合,涵盖工具使用、规划和多步骤推理。
Nemotron 代理安全数据集:近11,000 个AI 代理工作流程轨迹的集合,可帮助研究人员评估和减轻基于代理的系统中的新安全风险。
这些开放数据集与NVIDIA NemoGym、RL、Data Designer 和Evaluator 开放库一起,使开发人员能够训练、增强和评估自己的Nemotron 模型。
探索NemotronGitHub:预训练和强化学习解决方案
NVIDIA 维护着一个开放的Nemotron GitHub 存储库,其中包含:
预训练程序(已发布),展示了Nemotron3 Nano的训练过程
多环境优化的强化学习对齐方案
数据处理管道、分词器配置和长上下文设置
后续更新将添加更多训练后和微调解决方案
如果您想训练自己的Nemotron、扩展Nano 或创建特定于域的变体,GitHub 存储库提供了文档、配置和工具来重现从头到尾的关键步骤。
这种开放性形成了闭环:您可以运行和部署模型、检查它们的构建方式,甚至训练您自己的模型,所有这些都仅使用NVIDIA 开放资源。
Nemotron3 Nano 现已上线。立即开始使用NVIDIA 的开放模型、开放工具、开放数据和开放训练基础设施来构建长上下文、高吞吐量的基于代理的系统。
Nemotron 模型推理挑战赛
加速开放研究是Nemotron 团队的核心使命。为此,我们很高兴地宣布一项新的社区竞赛,旨在使用Nemotron 的开放模型和数据集来提高Nemotron 的推理性能。
关于作者
Chris Alexiuk 是NVIDIA 的深度学习开发者倡导者,他创建技术资源来帮助开发者使用NVIDIA 提供的强大的AI 工具集。 Chris 拥有机器学习和数据科学背景,并对大型语言模型的所有事物充满热情。
Shashank Verma 是NVIDIA 深度学习领域的技术营销工程师。他负责开发和呈现有关各种深度学习框架的以开发人员为中心的内容。他在威斯康星大学麦迪逊分校获得了电气工程硕士学位,在那里他专注于计算机视觉、数据科学的安全方面和HPC。
Chintan Patel 是NVIDIA 的高级产品经理,致力于为HPC 社区带来GPU 加速的解决方案。他负责管理和配置NVIDIA GPU Cloud 注册表中的HPC 应用程序容器。在加入NVIDIA 之前,他曾在Micrel, Inc. 担任产品管理、营销和工程职位。他拥有圣克拉拉大学MBA 学位以及加州大学伯克利分校电气工程和计算机科学学士学位。