如何在NVIDIA CUDA Tile中编写高性能矩阵乘法
本博文是一系列课程的一部分,旨在帮助开发者学习NVIDIA CUDA Tile 编程并掌握构建高性能GPU 核心的方法,以矩阵乘法为核心示例。
在本文中您将了解到:
如何使用NVIDIAcuTile实现高性能矩阵乘法:深入理解tile加载、计算和存储的执行过程。
块级并行编程思维的变化:从线程级思维逐渐过渡到以线程块为核心的编程模型。
Tile编程优化实践:通过实际代码掌握性能调优的关键策略。
在开始之前,请确保您的环境满足以下要求(有关更多详细信息,请参阅快速入门):
环境要求:
CUDA 13.1 或更高版本
GPU架构:NVIDIA Blackwell(例如NVIDIA RTX 50系列)
Python:3.10 及以上
安装cuTile Python:
pip install cuda-tile 注:cuTile 是NVIDIA 推出的新一代GPU 编程框架。尽管目前仅支持Blackwell(计算功能10.x 和12.x)架构的优化,但即将发布的CUDA 工具包版本将扩展对其他架构的支持。
什么是矩阵乘法?
矩阵乘法是现代技术计算中的基本运算。它是求解方程组的基础,支持图形处理、模拟、优化和大多数机器学习任务,并且可以有效映射到GPU 等高性能硬件。
给定输入矩阵A(MK)和B(KN),计算结果矩阵C(MN)中每个元素的公式如下。

从公式可以看出,矩阵C的元素是通过计算矩阵A的行和矩阵B的列的点积得到的。
分片编程可以通过将输出矩阵划分为多个分片来简化实现并获得优异的性能。每个tile负责计算输出矩阵的子块,cuTile自动处理内存访问和线程同步。具体来说:
每个块处理输出矩阵C 的(tmtn) 个图块。
沿着K维度循环,依次加载矩阵A和B对应的tile。
调用ct.mma()进行矩阵乘法和累加运算(Tensor Core自动启用)。
最后,将累加的结果写回全局存储器。
图1 以类似于逐元素算法的方式显示了计算过程,但在这种情况下,图块替换了单个元素。

图1. 分解为图块的矩阵乘法(A + B + C) 的图示
GPU内核实现
介绍完核心概念之后,我们来看一下完整的实现代码。代码分为两部分:一是在GPU上运行的内核,二是在CPU上启动的代码,如下所示。
导入cuda.tile 作为ct
从数学导入ceil
进口火炬
# 编译时常量的类型别名
ConstInt=ct.Constant[int]
# 步骤1: 定义内核
@ct.kernel
def matmul_kernel(A, B, C, tm: ConstInt, tn: ConstInt, tk: ConstInt):
# 1.1 获取块ID并映射到输出图块位置
# 在swizzle_2d 中,我们访问ct.bid(0) 并输出bidx 和bidy
bidx, bidy=swizzle_2d(M, N, tm, tn, GROUP_SIZE_M)
# 1.2 计算沿K维度的瓦片数量
num_tiles_k=ct.num_tiles(A, 轴=1, 形状=(tm, tk))
# 1.3 初始化累加器
累加器=ct.full((tm, tn), 0, dtype=ct.float32)
# 1.4 K维循环
对于范围内的k(num_tiles_k):
# 从A 和B 加载图块
a=ct.load(A, 索引=(bidx, k), 形状=(tm, tk))
b=ct.load(B, 索引=(k, bidy), 形状=(tk, tn))
#矩阵乘法累加
累加器=ct.mma(a, b, 累加器)
# 1.5 存储结果
ct.store(C,index=(bidx,bidy),tile=accumulator)
# 步骤2: 启动内核
def cutile_matmul(A: torch.Tensor, B: torch.Tensor) - torch.Tensor:
# 选择瓷砖尺寸
tm, tn, tk=128, 256, 64 # 对于float16
# 计算网格尺寸
grid_x=ceil(m/tm)
grid_y=ceil(n/tn)
网格=(网格_x * 网格_y, 1, 1)
# 创建输出并启动
C=torch.empty((m, n), device=A.device, dtype=A.dtype)
ct.launch(流,网格,matmul_kernel,(A,B,C,tm,tn,tk))
return C 现在,让我们一步步分解每个关键部分。
1. 定义GPU内核
在cuTile 中,@ct.kernel 装饰器用于将普通Python 函数标记为GPU 内核:
@ct.kernel
def matmul_kernel(A, B, C, tm: ConstInt, tn: ConstInt, tk: ConstInt):
# 内核代码这里这个装饰器的意思是:
该函数将在GPU 上执行。
每个线程块将运行该函数的一个独立实例。
它不能直接调用,必须通过ct.launch() 启动。
2. 编译时优化:常量类型的注释
请注意,参数tm、tn 和tk 使用特殊类型注释ct.Constant[int]:
ConstInt=ct.Constant[int] # 定义类型别名
def matmul_kernel(A, B, C,
tm: ConstInt, # 沿M 维度的平铺大小
tn: ConstInt, # 沿N 维度的平铺大小
tk: ConstInt): # 沿K 维度的平铺大小这表明它们是编译时常量。 cuTile 为不同的图块大小值生成专门的机器代码,允许编译器:
执行循环展开。
优化内存访问模式。
生成高效的Tensor Core 指令。
3. 确定工作范围:块ID 映射
每个块负责计算输出矩阵的特定块。通过swizzle_2d() 函数,我们得到当前正在处理的块的索引:
def swizzle_2d(M, N, tm, tn, GROUP_SIZE_M):
# 获取一维网格中当前CUDA 块(CTA)的全局ID。
出价=ct.出价(0)
返回swizzle_2d_from_bid(M, N, tm, tn, GROUP_SIZE_M, bid)
bidx, bidy=swizzle_2d(M, N, tm, tn, GROUP_SIZE_M)
该代码的功能是确定当前块应处理输出矩阵中的哪个图块。为了理解这个过程,我们首先从主机端的网格划分开始。
第1 步:主机端网格划分
在主机端启动内核函数时(如第3节所述),计算所需的任务块数量:
grid_x=ceil(m/tm) # M 维度所需的块数
grid_y=ceil(n/tn) # N 维所需的块数
grid_size=grid_x * grid_y # 总块数
grid=(grid_size, 1, 1) # 定义为一维gridm,n: 输出矩阵C 的行和列。
tm: 输出图块大小行方向(M 尺寸)由每个图块处理。
tn: 输出列方向(N 维)上每个块处理的分片大小。
从逻辑上讲,启动grid_x * grid_y 块并将其展平为一维网格:grid=(grid_size, 1, 1)。
步骤2:获取内核中的块ID
在内核内部,每个块通过ct.bid(0) 获取其唯一标识符:
bid=ct.bid(0) # 返回值range: [0, grid_size-1]ct.bid(0) 查询当前区块在x轴维度的ID。
参数0 表示第一个维度(x 轴),对应于网格定义中的第一个元素(grid_size, 1, 1)。
每个块都有一个唯一的一维坐标:bid=0, 1, 2, …, grid_size-1。
步骤3:将1D 块ID 映射到2D 图块坐标
现在的问题是块ID(bid)是一维的,而输出矩阵是二维的。需要明确该块应该处理哪些行块和列块。 swizzle_2d_from_bid() 函数可用于确定该块负责的行和列图块。
bidx, bidy=swizzle_2d_from_bid(M, N, tm, tn, GROUP_SIZE_M, bid) 输出结果:
bidx:当前块负责的输出瓦片的M维度中的行索引。值范围:[0, grid_x -1]。
bidy:当前块负责的输出瓦片的N维中的列索引。取值范围:[0, grid_y -1]。
具体的映射逻辑涉及到Swizzling(用于提高内存访问效率),我们将在第4节详细解释。现在,只需理解它将1D块ID转换为2D瓦片坐标。
5. 准备累加器:初始化输出图块
在循环K 维之前,需要创建一个累加器来存储中间结果:
num_tiles_k=ct.num_tiles(A, 轴=1, 形状=(tm, tk))
Accumulator=ct.full((tm, tn), 0, dtype=ct.float32)num_tiles_k: 计算K 维中要处理的图块数量。
accumulator: 用于累积结果的形状(tm, tn) 的零矩阵。
使用float32 可确保数值精度并避免累积误差。
6.核心计算循环:沿K维度遍历
这就是矩阵乘法的核心。接下来,循环K 维度中的每个图块并累加结果:
对于范围内的k(num_tiles_k):
#加载图块
a=ct.load(A, 索引=(bidx, k), 形状=(tm, tk), padding_mode=zero_pad)
b=ct.load(B, 索引=(k, bidy), 形状=(tk, tn), padding_mode=zero_pad)
#积累
Accumulator=ct.mma(a, b, accumulator) 加载数据:
ct.load(A, index=(bidx, k), shape=(tm, tk)): 从矩阵A 加载图块。
index=(bidx, k): 指定要加载到图块空间中的图块坐标。
shape=(tm, tk): 图块的大小。
padding_mode=zero_pad: 如果有效负载数据超出范围,则填充0。
矩阵乘法和累加:
ct.mma(a, b, accumulator): a*b相乘,加到累加器,然后将结果保存到累加器(mma表示矩阵乘法累加)
当a和b的形状满足Tensor Core要求时,cuTile会自动调用GPU的Tensor Core来加速此操作。
循环结束后,累加器保存输出图块的完整结果。
写回结果:存储到全局内存
随后,计算结果被写回全局内存:
累加器=ct.astype(累加器, C.dtype)
ct.store(C,index=(bidx, bidy),tile=accumulator) 首先,将float32累加器转换为输出矩阵的数据类型。
使用ct.store() 将图块写回到全局内存中的相应位置。
启动内核函数:主机端代码
现在从主机引导内核。首先看一下整个代码。
def cutile_matmul(A: torch.Tensor, B: torch.Tensor) - torch.Tensor:
# 根据dtype 确定图块大小
if A.dtype.itemsize==2: # float16/bfloat16
tm、tn、tk=128、256、64
else: # float32
tm, tn, tk=32, 32, 32
m, k=A.形状
_, n=B.形状
# 计算网格尺寸
grid_x=ceil(m/tm)
grid_y=ceil(n/tn)
网格大小=网格x * 网格y
网格=(网格大小, 1, 1)
#创建输出张量
C=torch.empty((m, n), device=A.device, dtype=A.dtype)
# 启动内核
ct.launch(torch.cuda.current_stream(), 网格, matmul_kernel,
(A、B、C、tm、tn、tk))
return C 在主机端启动内核需要完成三个关键步骤:
第1 步:计算网格大小
根据输入矩阵的维度和图块大小,计算所需图块的数量:
m, k=A.shape # 矩阵A维度: m行,k列
_, n=B.shape # 矩阵B维度: k行,n列
# 计算所需的块数
grid_x=ceil(m/tm) # M 维度需要多少个瓦片
grid_y=ceil(n/tn) # N 维需要多少个瓦片
grid_size=grid_x * grid_y # 总块数
grid=(grid_size, 1, 1) # 定义为1D gridceil() 向上舍入以确保覆盖所有元素(即使矩阵维度不能被图块大小整除)。
将2D 块布局展平为1D 网格可简化启动逻辑。
第2 步:设置图块大小(编译时常量)
根据数据类型选择合适的切片大小:
if A.dtype.itemsize==2: # float16/bfloat16(每个元素2 个字节)
tm、tn、tk=128、256、64
else: # float32(每个元素4 个字节)
tm, tn, tk=32, 32, 32 这些参数作为编译时常量传递给内核:
tm: 输出图块行(M 尺寸)。
tn: 输出图块列(N 维)。
tk: 每个负载的瓷砖尺寸(K 尺寸)。
注意:此处的图块尺寸配置仅作为示例。在实际应用中,不同的GPU架构需要相应的参数配置才能达到理想的性能。合适的配置取决于M/N/K大小、GPU架构、共享内存大小、寄存器数量、SM数量等因素。在开发过程中,建议使用NVIDIA Nsight Compute等性能分析工具来确定最佳参数。 TileGym提供了一个自动调优程序,可用于自动获取最佳参数。
第三步:调用ct.launch()启动内核函数
C=torch.empty((m, n), device=A.device, dtype=A.dtype) # 创建输出张量
ct.启动(
torch.cuda.current_stream(), # CUDA 流
grid, # 网格尺寸: (grid_size, 1, 1)
matmul_kernel, # 核函数
(A, B, C, tm, tn, tk) # 传递给内核的参数
)Stream:指定内核函数在哪个CUDA流上执行(用于实现异步执行和多流并发)。
网格:定义要启动的线程块的数量。
内核函数:要执行的GPU内核(即用ct.kernel修饰的函数)。
参数元组: 传递给内核的所有参数;其中tm、tn 和tk 将被编译器识别为常量。
性能优化:Swizzle
为了提高性能,我们早期引入了Swizzle。如swizzle_2d_from_bid的代码所示。
def swizzle_2d_from_bid(M, N, tm, tn, GROUP_SIZE_M, bid):
# 获取一维网格中给定CUDA 块的全局ID。
num_bid_m=ct.cdiv(M, tm)
num_bid_n=ct.cdiv(N, tn)
组内竞价数=GROUP_SIZE_M * 竞价数n
group_id=bid //组中的num_bid_in_group
First_bid_m=group_id * GROUP_SIZE_M
group_size_m=min(num_bid_m - first_bid_m, GROUP_SIZE_M)
bid_m=first_bid_m + (出价% group_size_m)
bid_n=(bid % num_bid_in_group) //group_size_m
return bid_m, bid_nSwizzle 如何提高性能?
它以分组和交错的方式将块ID 重新映射到图块索引,以更有效地利用缓存。
该图以输出矩阵的四个元素(彩色区域)为例,比较线性内存访问和Swizzled内存访问。
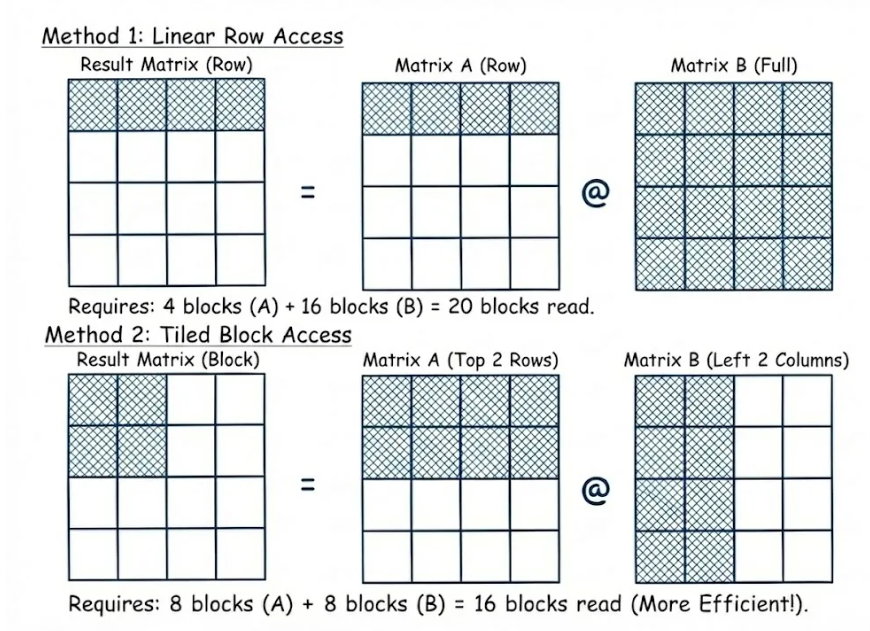
图2. 线性行访问和块瓦片访问的直观比较
方法一:线性行访问
当计算结果矩阵中的一行数据(例如四个元素)时,
需要读取左侧矩阵的4 个块和右侧矩阵的所有16 个块。
总内存访问:20 个数据块。
由于正确的矩阵数据被频繁加载并快速替换,导致缓存命中率降低。
方法2:混合/平铺访问
将计算重新组织为2 2 局部块。
只需要读取左矩阵中的8个相关块和右矩阵中的8个相关块。
内存访问总量: 16 个数据块(减少20%)。
数据局部性更好,缓存命中率提高。
性能基准
为了验证所实现的矩阵乘法核心的性能,在NVIDIA GeForce RTX 5080(计算能力12.0)上进行了测试。完整的基准测试代码可以在TileGym 存储库中找到。根据安装说明完成配置后,请参考快速入门指南运行本次测试及其他相关测试。
测试配置:
数据类型: float16
矩阵形状: 标准方阵(NN)
测试尺寸: N=1024, 2048, 4096, 8192, 16384(即21 至214)
下图展示了不同矩阵大小下的性能。

图3. cuTile 和PyTorch 的TFLOP/s 性能比较(作为NVIDIA GeForce RTX 5080 上矩阵大小的函数)
结果显示:
在大矩阵规模下,cuTile实现可以充分释放GPU的计算能力。
通过合理的tile size配置和swizzle优化,cuTile的性能相比业界先进的实现(PyTorch称为cuBLAS)提升了90%以上。
总结
这个经典的矩阵乘法示例展示了使用cuTile 实现GPU 内核的完整过程。虽然矩阵乘法比较简单,但是它涵盖了Tile编程的核心思想。一旦掌握了这些概念,您将能够使用cuTile 来实现各种高性能GPU 内核。查看TileGym 库中完整的矩阵乘法示例和其他相关内容,立即开始编写高效的图块代码。
关于作者
Jinman Xie 是NVIDIA 的深度学习性能架构师。毕业于浙江大学计算机科学与技术学院。金曼的主要关注领域包括深度学习模型加速、内核优化和深度学习编译技术。
肖琪琪毕业于北京大学计算机科学专业,并获得卡内基梅隆大学硕士学位。 Qiqi专注于AI推理框架、深度学习模型优化和编译技术。