如何在STM32和Arduino上实现卷积神经网络
01前言在大多数情况下,实用的机器学习算法需要大量的计算资源(CPU 周期和内存占用)。不过,TensorFlow Lite 最近推出了一个实验版本,可以在各种微控制器上运行。如果我们能够构建适用于资源受限设备的模型,我们就可以开始将嵌入式系统转变为TinyML 设备。
TensorFlow Lite Micro(简称TFLM)是一个开源机器学习推理框架,专为在嵌入式系统上运行深度学习模型而设计。由于嵌入式系统存在资源限制和碎片化,跨平台互操作几乎不可能实现,而TFLM正好满足相关的效率要求。该框架使用基于解释器的设计,克服了这些独特的挑战,同时提供了灵活性。
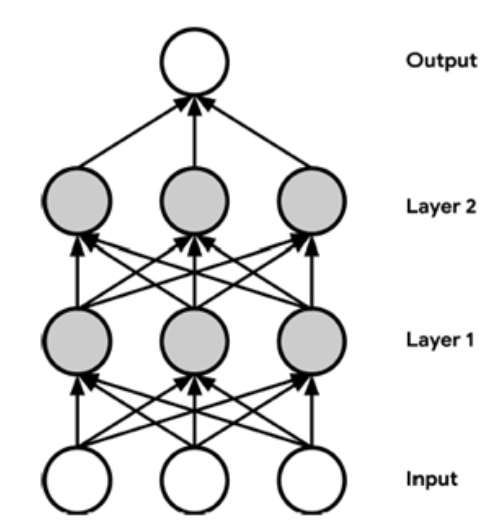
图1:一个简单的两层深度学习网络
02开发开发TFLM 应用程序的目标是在内存中创建有效的神经网络模型对象。应用程序开发人员需要通过客户端API 创建“运算符解析器”对象。 OpResolver API 控制与最终二进制文件关联的运算符并最小化文件大小。
第一步提供了一个连续的内存“区域”(arena),用于存储中间结果和解释器所需的其他各种变量。此步骤至关重要,因为嵌入式设备默认不支持动态内存分配。
第二步是创建一个编译的例子,并传入模型、算子解析器和内存区域作为参数。编译器在初始化阶段将操作所需的所有内存分配到该内存区域中。我们避免任何动态内存分配,以防止堆栈碎片在长时间运行的应用程序中导致错误。触发应用程序在模型评估阶段分配所需的内存,因此此时会调用算子初始化函数,并将其占用的内存转移给解释器。应用程序提供的运算符解析器(OpResolver)会将序列化模型中列出的运算符类型映射到相应的执行函数。 C语言API调用负责控制解释器和算子之间的所有通信,确保算子的实现是模块化的并且独立于解释器的内部细节。这种设计方法不仅允许开发人员轻松地将算子执行器实现替换为优化版本,而且还可以更轻松地重用其他系统的算子执行库(例如,作为代码生成项目的一部分)。
第三步是执行阶段。应用程序获取一个指向表示模型输入的内存区域的指针,然后用数据(通常来自传感器或其他用户提供的输入)填充它。输入数据准备好后,应用程序调用解释器来执行模型计算。该过程包括:遍历按拓扑排序的算子,利用内存规划阶段计算出的偏移量定位输入输出数据,并为每个算子调用相应的求值执行函数。
第四步,当所有操作员评估完成后,解释器会将控制权返回给应用程序。大多数微控制器(MCU) 都具有单线程架构,并依靠中断来处理紧急任务。这个办法是完全可行的。然而,应用程序仍然可以在单线程上运行,并且特定于平台的运算符仍然可以跨多个处理器分配计算任务。当解释器调用完成时,应用程序可以向解释器查询包含模型计算输出的数组的位置,然后使用该输出。
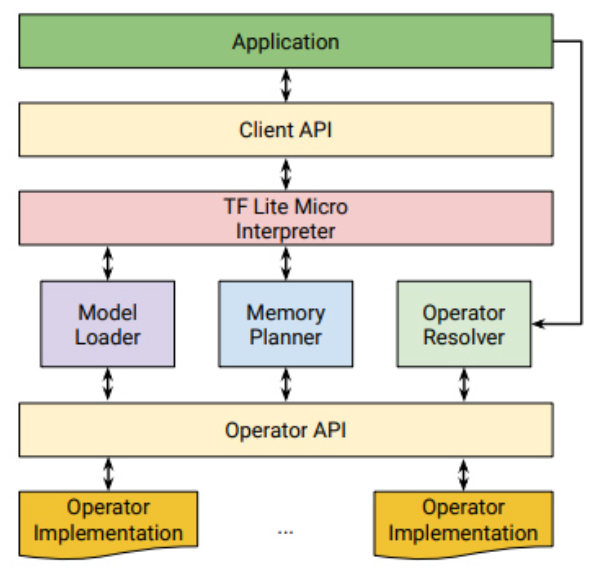
图2:实施模块概览
最后03Models built using Keras or TensorFlow need to be converted to TensorFlow Lite format and exported before they can be deployed to run on a microcontroller.我们可以借助TensorFlow Lite Converter 的Python API 来完成此转换。 This API takes our Keras model and writes it to disk in FlatBuffer format ——FlatBuffer is a special file format designed to improve space utilization.由于我们部署的目标设备是内存受限的微控制器,因此这种高效的文件格式将派上用场。
要将模型部署到STM32微控制器和Arduino平台,我们可以使用EloquentTinyML库进行无缝部署。 This is a library designed for running TinyML models on microcontrollers, eliminating the need for developers to deal with complex compilation processes and troubleshooting arcane error messages.
您必须首先安装最新版本的库(如果没有0.0.5版本,可以选择0.0.4版本)。安装可以通过Library Manager完成,也可以直接从Github平台下载安装。
部署04The following is sample code for running and deploying a digit recognition TinyML model on STM32 and Arduino microcontrollers.
向上滑动即可阅读
#include//copy the printed code from tinymlgen into this file #include'digits_model.h' #defineNUMBER_OF_INPUTS 64 #defineNUMBER_OF_OUTPUTS 10 #defineTENSOR_ARENA_SIZE 8*1024Eloquent:TfLite ml;voidsetup(){Serial.begin(115200);ml.begin(digits_model);}voidloop(){//a random sample from the MNIST dataset (precisely the last one)floatx_test[64]={0.0.0.625,0.875,0.5 ,0.0625,0.0.0.0.125,1.0.875,0.375,0.0625,0.0.0.0.0.9375,0.9375,0.5 ,0.9375,0.0.0.0.0.3125,1.1.0.625,0.0.0.0.0.75 ,0.9375,0.9375,0.75 ,0.0.0.0.25 ,1.0.375,0.25 ,1.0.375,0.0.0.5 ,1.0.625,0.5 ,1.0.5 ,0.0.0.0625,0.5 ,0.75 ,0.875,0.75 ,0.0625,0.};//the output vector for the model predictionsfloaty_pred[10]={0};//样本的实际类别inty_test=8;//让我们看看对样本进行分类需要多长时间uint32_tstart=micros();ml.predict(x_test, y_pred);uint32_ttimeit=micros() - start;Serial.print('It take ');Serial.print(timeit);Serial.println(' micros to run inference');//让我们print the raw predictions for all the classes//these values are not directly interpretable as probabilities!Serial.print('Test output is: ');Serial.println(y_test);Serial.print('Predicted proba are: ');for(inti=0; i 10; i++) {Serial.print(y_pred[i]);Serial.print(i==9?'':',');}//let's print the 'most probable' class//you can either use probaToClass() if you also want to use all the probabilitiesSerial.print('Predicted class is: ');Serial.println(ml.probaToClass(y_pred));//or you can skip the predict() method and call directly PredictClass()Serial.print('健全性检查:');Serial.println(ml.predictClass(x_test));延迟(1000);}
欢迎您点击“示例代码”访问element14官网。如果您有任何业务或订单相关问题,请拨打全国客服热线:阅读原文咨询element14相关产品。