如何在NVIDIA Jetson AGX Thor上部署1200亿参数大模型
上期介绍了如何使用Docker在NVIDIAJetson AGX Thor上部署vLLM推理服务,并使用Chatbox作为前端调用vLLM运行模型(链接至上期文章)。本期我们将尝试是否可以在Jetson AGX Thor 上部署并成功运行一个参数高达1200 亿的大型gpt-oss-120b 模型。
gpt-oss-120b是OpenAI今年发布的开放权重AI模型,采用流行的混合专家模型(MoE)架构和SwigGLU激活函数。其注意力层采用RoPE技术,上下文大小为128k,与完整上下文和长度为128个Token的滑动窗口交替。该模型具有FP4 精度,可以在NVIDIA Blackwell 架构GPU 上运行。
本期具体内容包括:
vLLM镜像下载和容器构建
模型下载并运行
使用Chatbox 作为前端调用gpt-oss-120b
Jetson AGX Thor模型运行资源使用情况及性能
一、vLLM 镜像下载及容器构建参考之前的教程拉取vLLM镜像并构建容器。
1. 在命令行运行docker pull nvcr.io/nvidia/vllm:25.10-py3下载容器。
2. 下载完成后,运行容器,创建启动命令。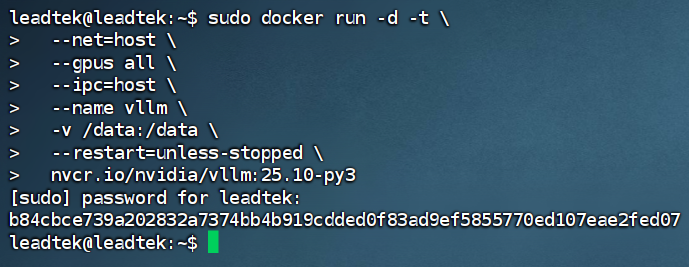
3. 容器创建成功后,使用docker exec -it vllm /bin/bash命令进入此容器。
二、模型下载与运行1. 在线下载模型并运行1.1 登录 Hugging Face,下载 gpt-oss-120b 模型。在容器中执行huggingface-cli登录并输入Hugging Face令牌。如果出现“登录成功”则表示登录成功。
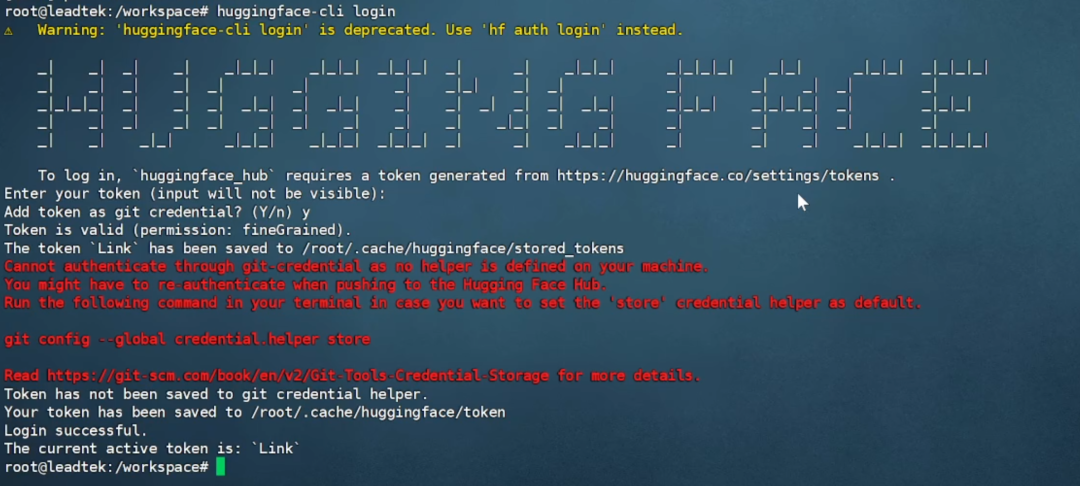
注:获取token需注册并登录huggingface.co,点击右上角的用户头像-Access Tokens,然后在新页面点击Create new token,输入token名称,最后点击底部的Create token,复制并保存。
上下滑动查看图片
1.2 容器内运行vllm serve openai/gpt-oss-120b,从 Hugging Face 上在线下载模型并开始运行。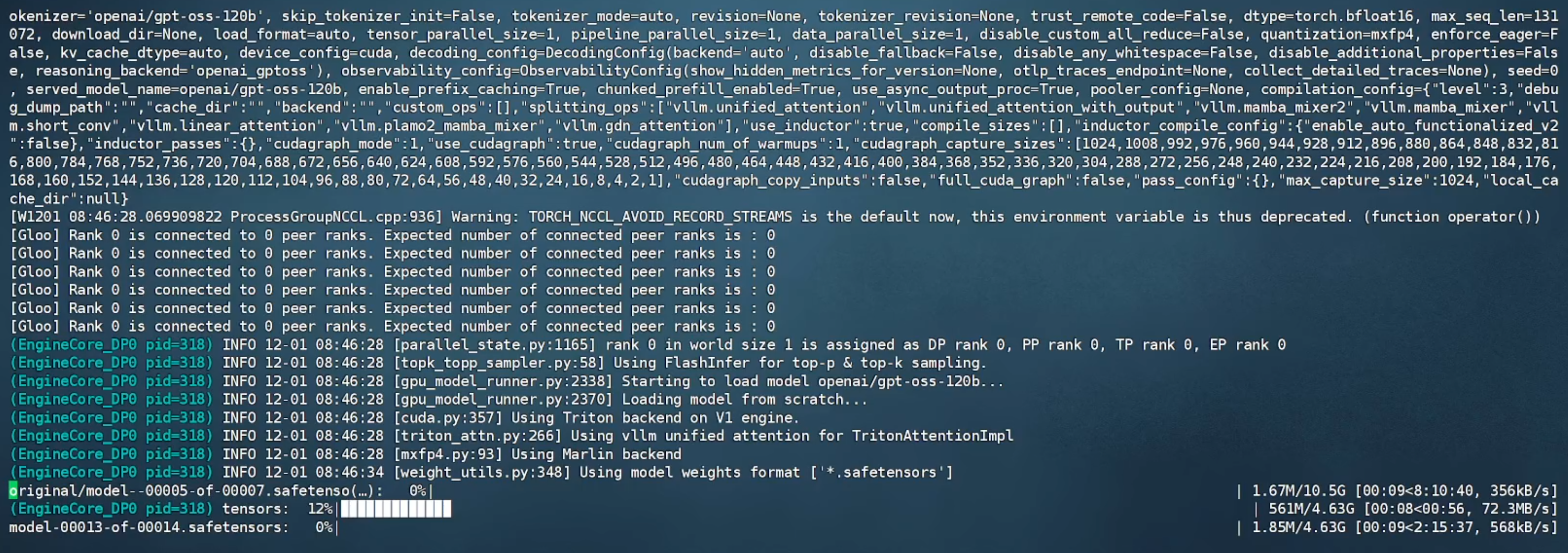
1.3 等待模型文件下载完成后(需科学上网),出现 API 端口号即可进行调用。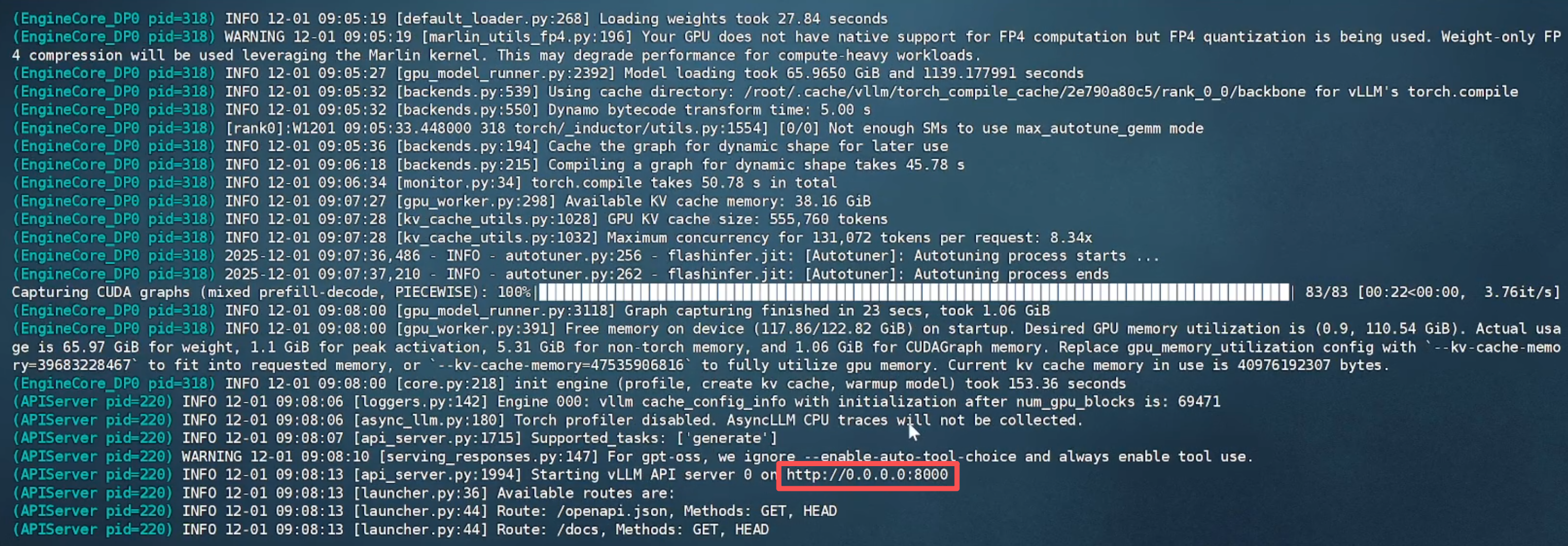
2. 本地模型运行上述方法会将模型文件下载到容器的默认目录下,再次运行时会直接调用下载的文件。为避免删除容器导致文件丢失,建议将模型文件复制到本地映射目录(如/data)保存。
以当前路径为例,在命令行执行以下代码,保存到本地指定目录:
cp-r 模型--openai--gpt-oss-120b /data

我们将本地模型文件命名为:local/gpt-oss-120b。在容器中命令行执行以下命令即可正常运行本地模型:
vllm 服务/数据/模型--openai--gpt-oss-120b/snapshots/b5c939de8f754692c1647ca79fbf85e8c1e70f8a --served-model-name'local/gpt-oss-120b'
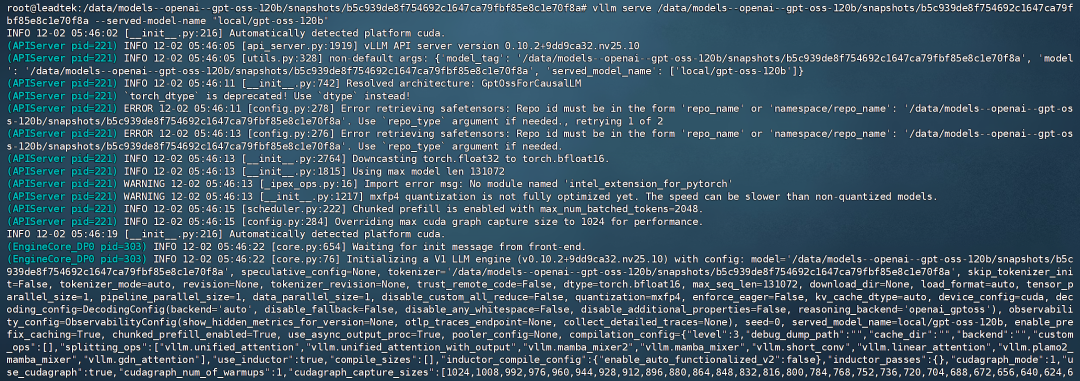
模型运行成功:
三、使用 Chatbox 作为前端调用 gpt-oss-120bChatbox AI 是一款AI 客户端应用程序和智能助手,支持许多高级AI 模型和API,可在Windows、MacOS、Android、iOS、Linux 和Web 上使用。这里,可以选择Chatbox作为前端,调用vLLM运行的gpt-oss-120b模型,与AI进行本地或在线对话。
1.参考上期教程,局域网内下载安装 Chatbox Windows 版本,点击“设置提供方” — “添加”,输入模型名称,再次点击“添加”。

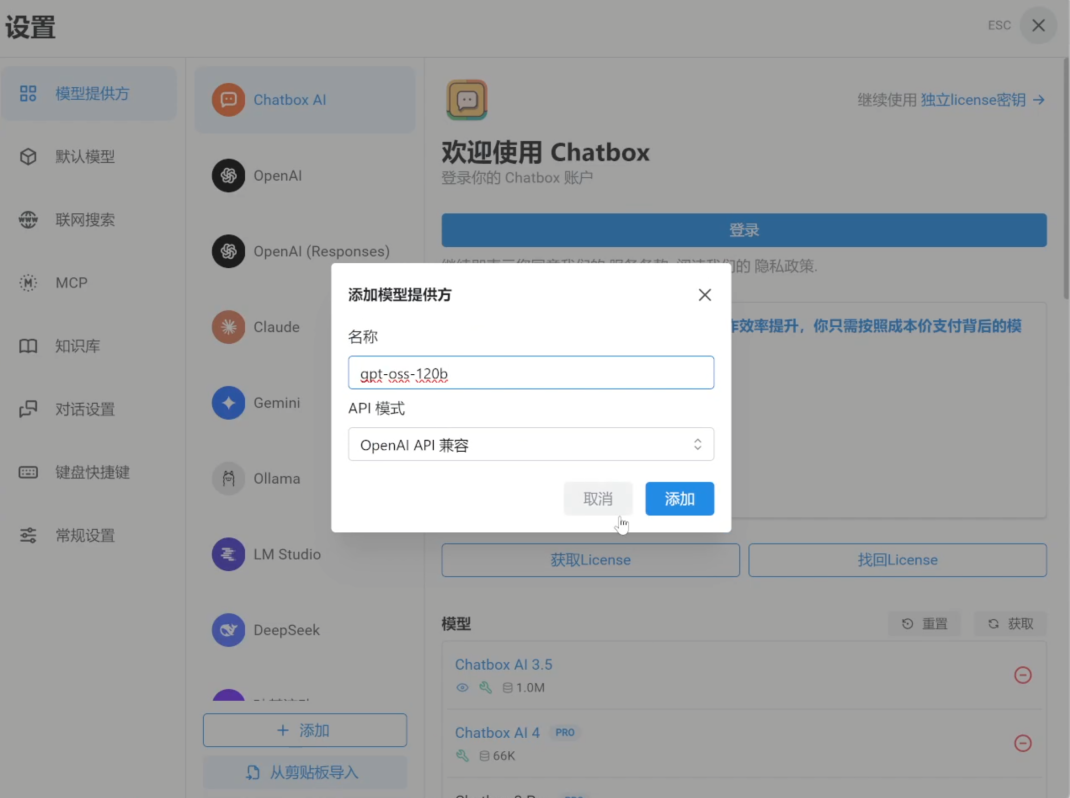
上下滑动查看图片
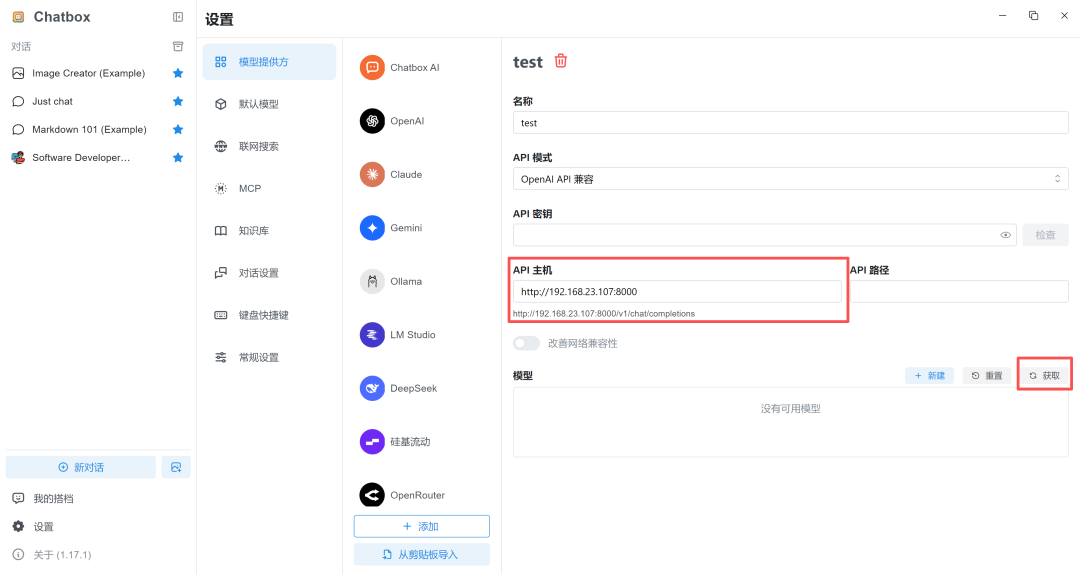
2. API 主机可输入 Jetson AGX Thor 主机 IP 以及 vLLM 服务端口号。(示例:http://192.168.23.107:8000)
3. 选择 vLLM 运行的模型,点击“+”。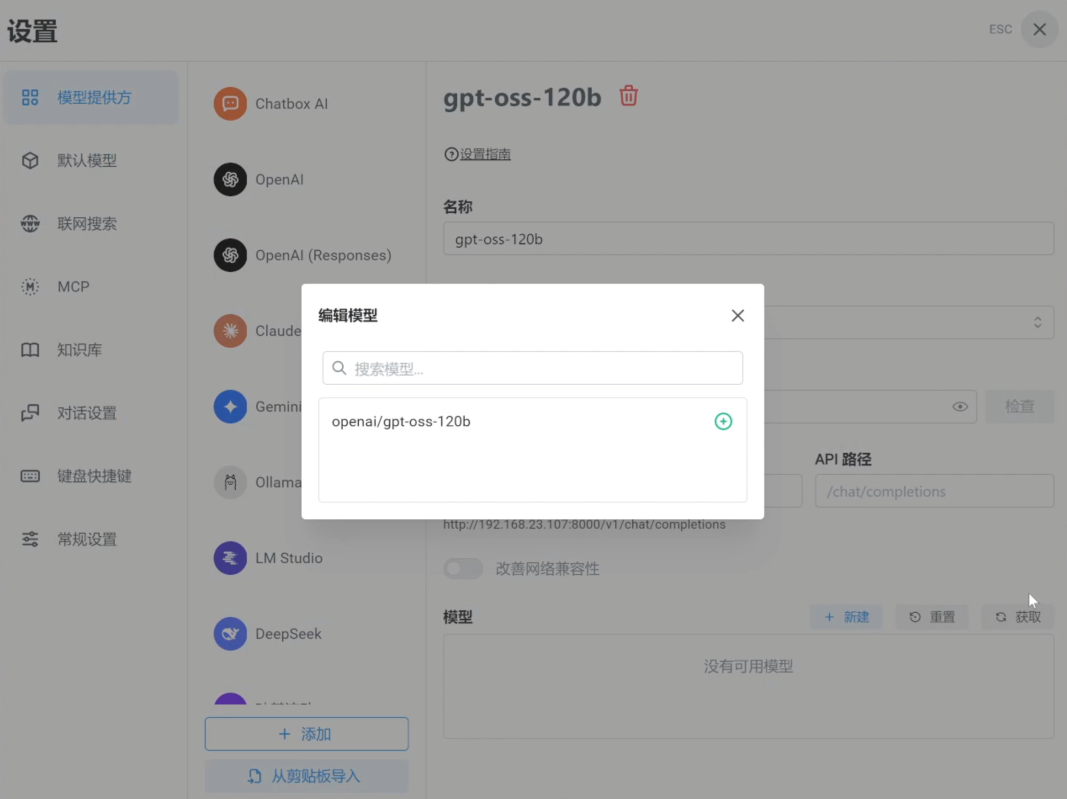
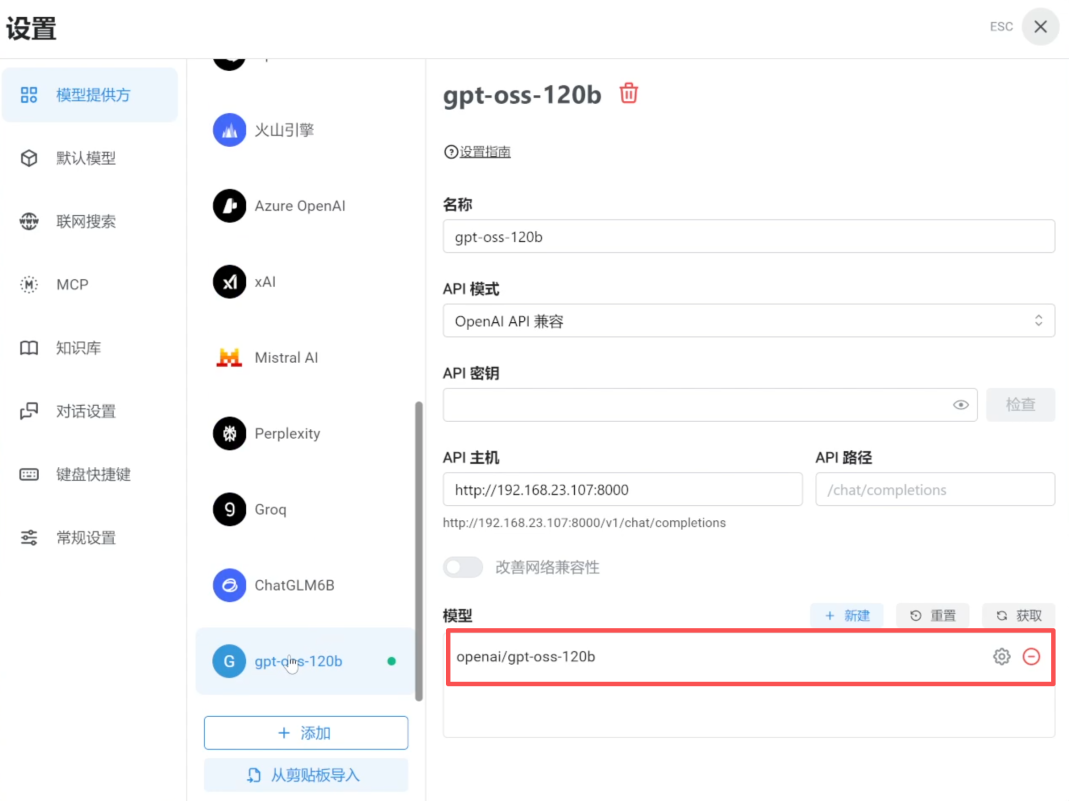
注:前面步骤中保存的或通过其他方式获取的模型文件也可以添加到此处。
4. 点击“新对话”,右下角选择该模型即可开启对话。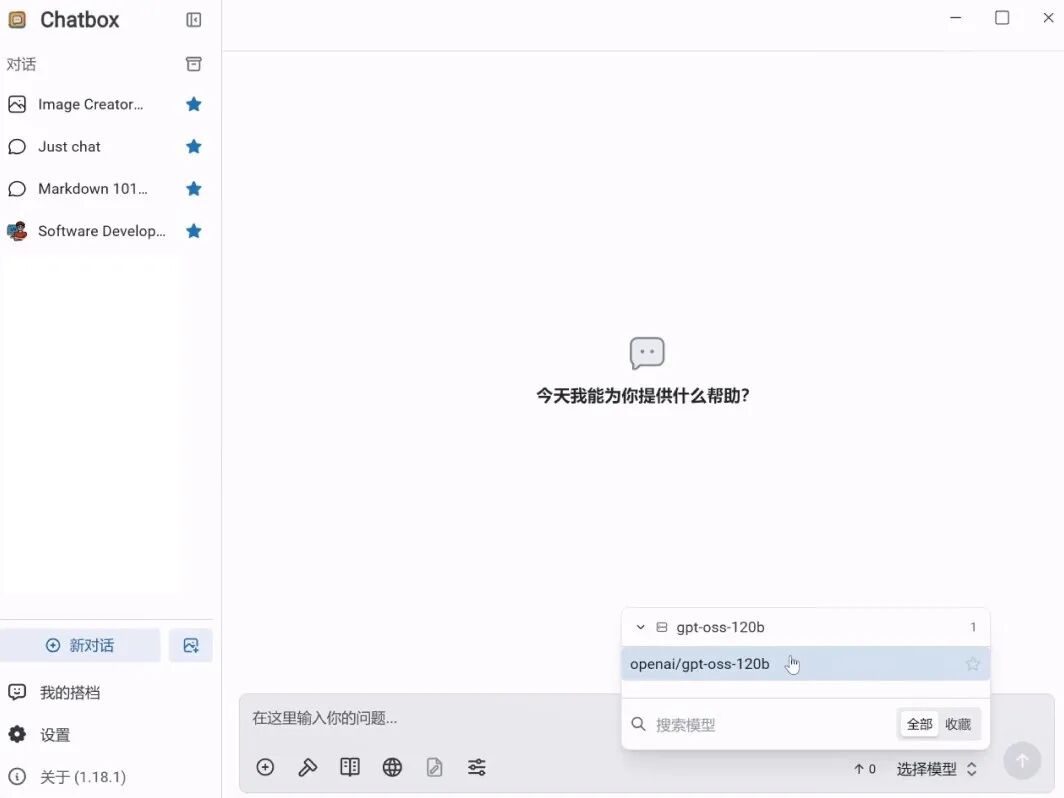
5. 运行示例本例中我们提出一个问题,结果如下:
以上视频已加速3倍
四、Jetson AGX Thor 模型运行资源占用及性能接下来分析运行gpt-oss-120b时的资源使用情况。
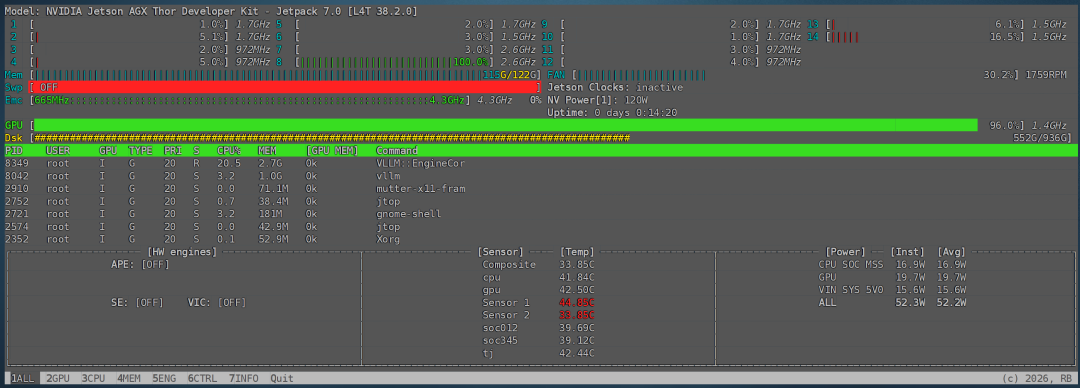
在命令行中执行jtop命令。可以看到,加载模型后,内存使用量约为115G。

模型在执行推理任务时,部分CPU核心持续满载,GPU使用率保持在95%左右的高位。
我们使用AI生成的脚本来测试输入128个token、输出128个token、并发数为1时的吞吐量。
在容器内执行:
# 创建测试脚本cat /tmp/test_performance.py 'EOF'importtimeimportrequestsimportjsonimportstatistics# 配置API_URL='http://localhost:8000/v1'MODEL_NAME='local/gpt-oss-120b'NUM_REQUESTS=30# 提示生成约128 个token(英文)prompt_words=[]# 添加一些常用词到达约128 个token foriinrange(32): Prompt_words.append(f'Sentence{i+1}: 人工智能正在通过自动化和数据分析改变各个行业。')prompt=' '.join(prompt_words)print(f'提示长度(words):{len(prompt.split())}')results=[]total_tokens=0print(f'以{NUM_REQUESTS}个请求开始基准测试.')print(f'Model:{MODEL_NAME}')print(f'输入标记: ~128,输出标记: 128')print('-'*60)foriinrange(NUM_REQUESTS):有效负载={ 'model': MODEL_NAME, 'prompt': 提示,'max_tokens':128,'温度':0.1,'top_p':0.9 } try: start_time=time.time() response=requests.post( f'{API_URL}/completions', json=payload, timeout=300 ) end_time=time.time() ifresponse.status_code==200: result=response.json() Latency=end_time - start_time results.append(latency) # 估计生成的token 数量generated_text=result['choices'][0]['text'] output_tokens=len( generated_text.split()) Total_tokens +=128+ output_tokens # 输入+ 输出print(f'Request{i+1:3d}: 延迟={latency:2f}s,output_tokens={output_tokens}') else: print(f'Request{i+1:3d}: 失败,状态为{response.status_code}') exceptExceptionase: print(f'Request{i+1:3d}: Error -{e}') # 延迟一点,避免压力过大time.sleep(0.1)# 计算统计信息ifresults: Total_time=sum(results) avg_latency=statistics.mean(results)throughput_tokens=total_tokens /total_time # 计算百分位数sorted_latcies=sorted(results) p50=排序_延迟[int(len(排序_延迟)* 0.5)] p95=排序_延迟[int(len(排序_延迟)* 0.95)] p99=排序_延迟[int(len(排序_延迟)* 0.99)]打印(''+'='* 60)打印('性能结果')打印('='* 60) print(f'Model:{MODEL_NAME}') print(f'总请求数:{NUM_REQUESTS}') print(f'成功请求:{len(results)}') print(f'总测试时间:{total_time:2f}s') print(f'延迟统计:') print(f' 平均值延迟:{avg_latency:2f}s') 打印(f' P50 延迟:{p50:2f}s') 打印(f' P95 延迟:{p95:2f}s') 打印(f' P99 延迟:{p99:2f}s') print(f'Throughput:') print(f' 令牌总数:{total_tokens}') print(f' 吞吐量:{throughput_tokens:2f}令牌/秒') print(f' 每个请求的平均值:{total_tokens/len(results):1f}令牌') print('='*60)else: print('没有成功的请求!')EOF
左右滑动查看完整代码
命令行执行:
蟒蛇/tmp/test_performance.py
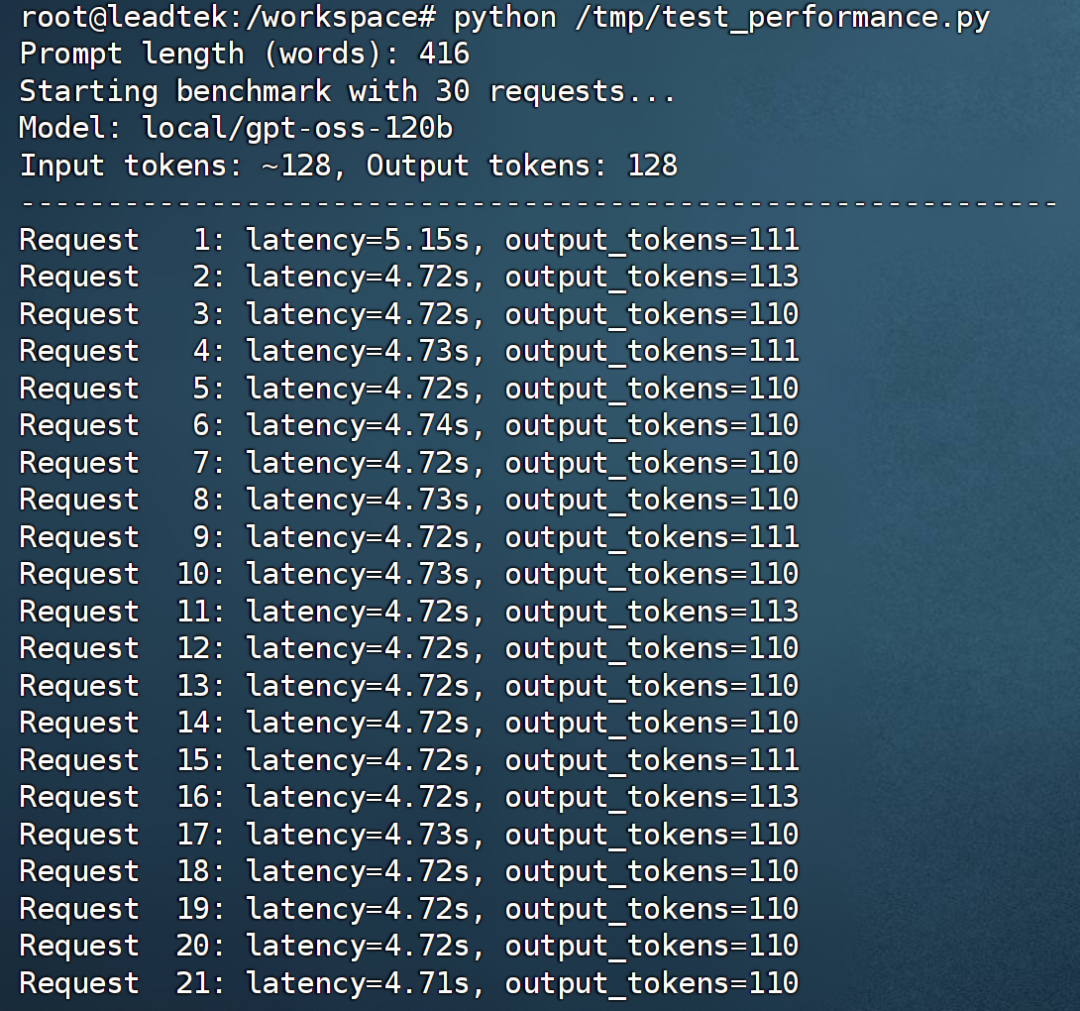
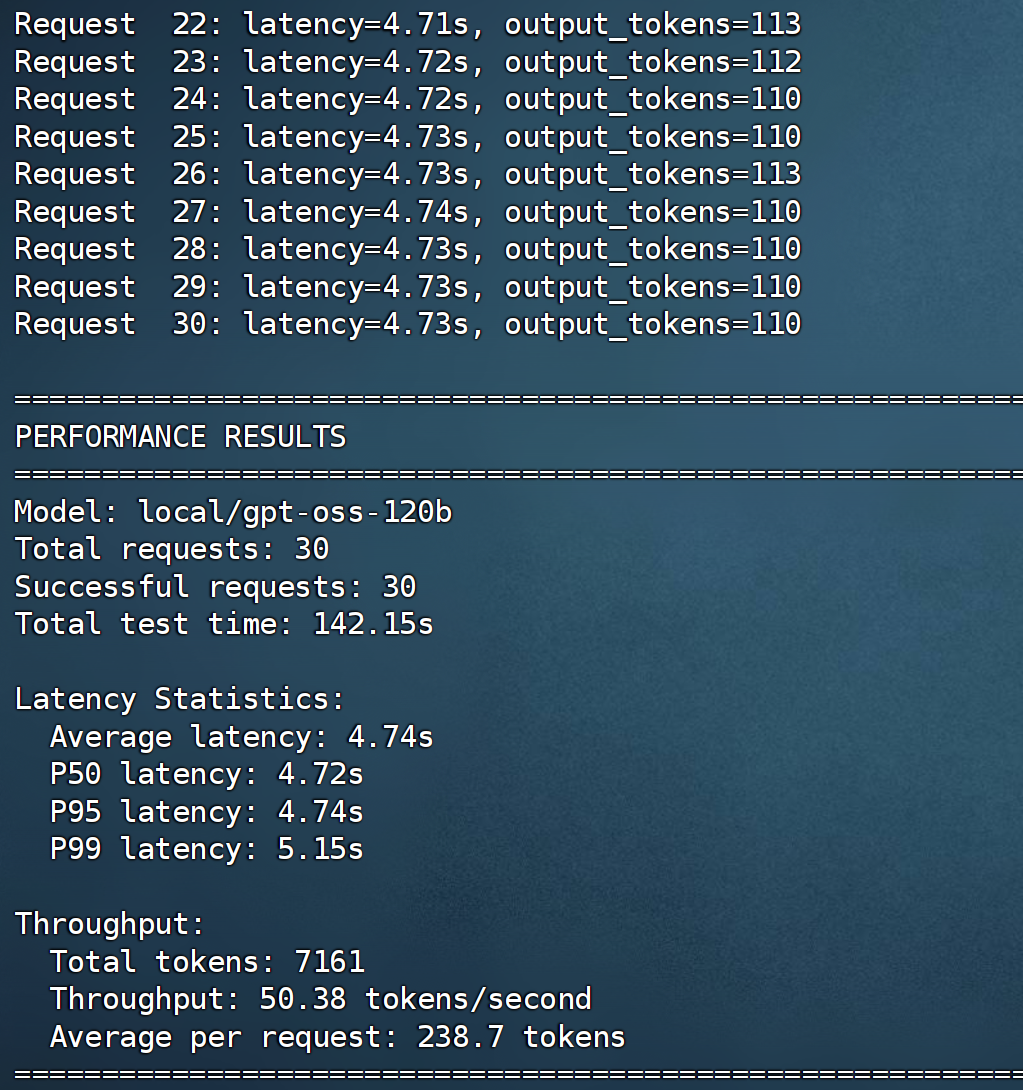
根据上图测试结果,在单用户条件下,输入/输出长度为128个token,并发数为1,系统吞吐量达到50.38 tokens / second。这意味着1200亿个参数模型可以在Jetson AGX Thor上流畅运行。