如何在NVIDIA Jetson Thor上提升机器人感知效率
借助NVIDIA 视觉编程接口库(VPI),您可以更高效地利用Jetson Thor 的计算能力。
构建自主机器人需要可靠且低延迟的视觉感知能力,以实现动态环境中的深度估计、障碍物识别、定位和导航。这些功能对计算性能有很高的要求。虽然NVIDIA Jetson平台为深度学习提供了强大的GPU支持,但随着AI模型复杂度的增加以及对实时性能的更高要求,GPU可能面临过载的风险。如果所有传感任务完全依赖GPU来执行,不仅容易造成性能瓶颈,还可能导致功耗和散热压力增加。这在功耗有限、散热条件有限的移动机器人应用中尤为突出。
为了应对上述挑战,NVIDIA Jetson 平台将高性能GPU 与专用硬件加速器相结合。 Jetson AGX Orin 和Jetson Thor 等平台配备专用硬件加速器,旨在高效执行图像处理和计算机视觉任务,释放GPU 资源以专注于更复杂的深度学习工作负载。 NVIDIA 可视化编程接口(VPI)进一步充分激活不同类型硬件加速器的性能潜力。
在本博客中,我们将探讨使用这些加速器的好处,并详细介绍开发人员如何通过VPI 充分利用Jetson 平台的性能潜力。作为示例,我们将展示如何使用这些加速器来开发低延迟、低功耗的立体视差感知应用程序。首先,我们将构建单通道立体摄像机工作流程,然后扩展到多流工作流程,支持8 通道立体摄像机在Thor T5000 上同时以30 FPS 运行。与Orin AGX 64 GB相比,其性能提升至10倍。
在开始开发之前,让我们快速了解一下Jetson平台提供的各种加速器、它们的优势、能够支持哪些应用场景以及VPI如何辅助开发。
除了GPU 之外,Jetson 还配备了哪些加速器?
Jetson 设备配备了适合深度学习任务的强大GPU,但随着AI 复杂性的增加,GPU 资源的高效管理变得越来越重要。 Jetson 为计算机视觉(CV) 工作负载提供专用硬件加速引擎。这些引擎与GPU 协同工作,可显着提高计算效率,同时保持灵活性。通过VPI,开发人员可以更方便地访问这些硬件资源,简化实验流程并实现高效的负载分配。
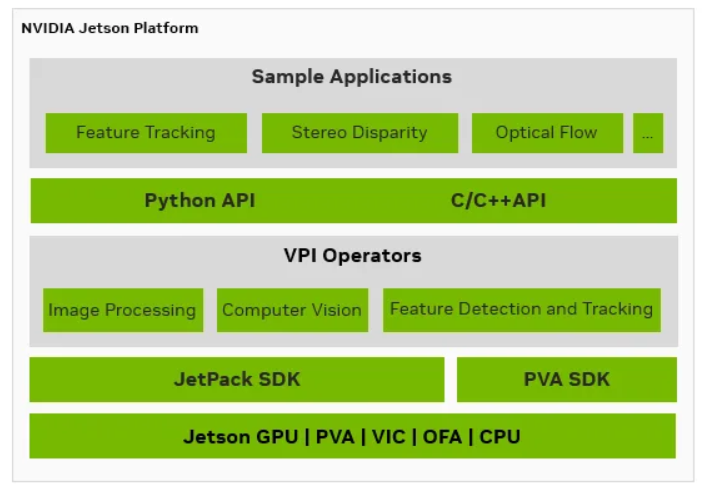
图1:面向Jetson 开发人员的可视化编程接口(VPI)
下面我们将仔细研究每个加速器、其用途和优点。
可编程视觉加速器(PVA):
PVA 是一种可编程数字信号处理(DSP) 引擎,配备超过1024 位单指令多数据(SIMD) 单元和具有灵活直接内存访问(DMA) 的本地内存。它针对视觉和图像处理任务进行了优化,并提供出色的每瓦性能。它与CPU、GPU 和其他加速器异步运行,可在除NVIDIA Jetson Nano 之外的所有Jetson 平台上使用。
通过VPI,开发人员可以调用现成的算法,例如AprilTag检测、对象跟踪和立体视差估计。对于需要自定义算法的场景,Jetson 开发者现在还可以使用PVA SDK,它提供了C/C++ API 和相关工具,支持直接在PVA 上开发视觉算法。
光流加速器(OFA):
OFA 是一种固定功能硬件加速器,用于根据立体相机对的数据计算光流和立体视差。 OFA支持两种工作模式:视差模式下,通过处理立体相机的左右校正图像生成视差图;在光流模式下,它用于估计两个连续帧之间的二维运动矢量。
视频和图像合成器(VIC):
VIC 是Jetson 设备中的专用硬件加速器,具有固定功能,可以高效节能的方式处理图像缩放、重映射、扭曲、色彩空间转换和降噪等基本图像处理任务。
哪些用例可以从这些加速器中受益?
在某些场景下,开发者可能会考虑使用GPU以外的解决方案,以更好地满足特定应用的需求。
GPU 资源过载应用: 为了实现高效运行,开发人员应优先将深度学习(DL) 工作负载分配给GPU,同时使用VPI 将计算机视觉任务卸载到PVA、OFA 或VIC 等专用加速器。例如,DeepStream 的Multi+ Object Tracker 如果仅依赖GPU,在Orin AGX 平台上可以处理12 个视频流。通过引入PVA实现负载均衡,支持的视频流数量可以增加到16路。
对于功耗敏感的应用,在哨兵模式或连续监控等场景下将主要计算任务转移到低功耗加速器(如PVA、OFA和VIC)上,有助于显着提高效率。
对于有热限制的工业应用,可以在高温运行环境下有效地将任务分配给各个加速器,以有效降低GPU负载并减少过热导致的性能节流,从而在有限的热预算内保持稳定的延迟和吞吐量性能。
如何使用VPI解锁所有加速器
VPI 提供了一个统一且灵活的框架,允许开发人员无缝访问不同平台上的加速器,例如Jetson 模块、工作站或具有独立GPU 的PC。
现在让我们看一个结合了上述内容的示例。
示例:立体视觉工作流程
现代机器人系统通常采用被动立体视觉技术来实现对周围环境的三维感知。因此,计算立体视差图成为构建复杂感知系统的关键环节。本文将介绍一个示例流程,帮助开发人员生成立体视差图及其对应的置信度图。同时,我们将展示如何使用VPI提供的各种加速器来构建低延迟和节能的处理工作流程。
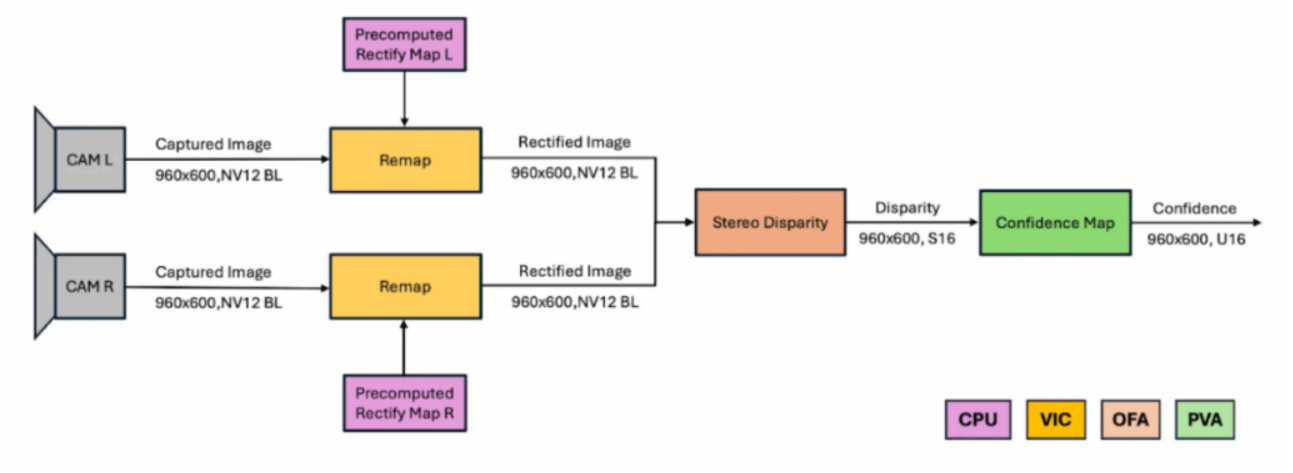
图2:部署在Jetson 多加速器上的立体视觉流程示意图。 PVA+:可编程视觉阵列; VIC:视频和图像合成器; OFA:光流加速器。
CPU 上的预处理:预处理步骤可以在CPU 上运行,因为它只发生一次。此步骤计算校正图,以校正立体相机帧中的镜头畸变。
VIC 上的重新映射:此步骤使用预先计算的校正图来去扭曲和对齐相机框架,确保两个光轴水平且平行。 VPI 支持多项式和鱼眼畸变模型,并允许开发人员定义自定义扭曲映射。请参阅重映射文档了解更多详细信息。
在OFA 上计算立体视差:校正后的图像对作为半全局匹配(SGM) 算法的输入。在实际应用中,SGM可能会产生噪声或错误的视差值。通过生成置信图,可以消除低置信度视差估计,从而提高结果的质量。有关SGM 算法及其支持参数的更多信息,请参阅立体视差文档。
在PVA上生成置信图:VPI提供三种置信图模式:绝对值(Absolute)、相对值(Relative)和推断(Inference)。绝对值和相对值模式需要两个OFA通道(左/右视差)并与PVA的交叉检查机制相结合;而推理模式只需要一个OFA 通道,并在PVA 上运行一个轻量级CNN(包含两个卷积层和两个非线性激活层)。虽然跳过置信度计算速度更快,但它会产生嘈杂的视差图;相比之下,使用相对值或推理模式可以显着提高视差结果的准确性和可靠性。
VPI的统一内存架构避免了不必要的跨引擎数据复制,其异步流和事件机制使开发人员能够提前规划任务负载和同步点。硬件管理调度支持跨引擎并行执行,通过高效的流处理设计释放CPU资源并避免延迟。
使用VPI 构建高性能立体视差工作流程
开始使用Python API
本教程介绍如何使用VPI Python API 实现基本的立体视差工作流程,而无需图像重新映射。
需要提前准备:
NVIDIA Jetson 设备(例如Jetson AGX Thor)
通过NVIDIA SDK Manager 或apt 安装VPI
Python 库:vpi、numpy、Pillow、opencv-python
在本教程中,我们将:
加载左右立体图像
转换图像格式以满足处理需求
同步数据流以确保信息准备就绪
执行立体匹配算法计算视差
后处理并保存输出结果
设置和初始化
第一步是导入所需的库并创建VPIStream 对象。 VPIStream充当命令队列,可用于提交异步执行的任务。为了演示并行处理,我们将使用两个流。
import vpiimport numpy as npfrom PIL import Imagefrom argparse import ArgumentParser # 创建两个流进行并行处理streamLeft=vpi.Stream()streamRight=vpi.Stream()
StreamLeft用于处理左图像,streamRight用于处理右图像。
加载和转换图像
VPI 的Python API 直接与NumPy 数组配合使用。我们首先通过Pillow加载图像,然后使用VPI的asimage函数将其封装成VPI图像对象。接下来,图像被转换为适合立体匹配算法的格式。在此示例中,图像将从RGBA8 格式转换为Y8_ER_BL 格式(即8 位灰度、块线性布局)。
# 加载图像并将其包装在VPI images中left_img=np.asarray(Image.open(args.left))right_img=np.asarray(Image.open(args.right))left=vpi.asimage(left_img)right=vpi.asimage(right_img) # 在不同后端并行将图像转换为Y8_ER_BL格式left=left.convert(vpi.Format.Y8_ER_BL,比例=1,流=streamLeft,后端=vpi.Backend.VIC)右=右.convert(vpi.Format.Y8_ER_BL,比例=1,流=streamRight,后端=vpi.Backend.CUDA)
左边的图像通过streamLeft提交给VIC后端处理,右边的图像通过streamRight提交给NVIDIA CUDA后端处理。这种设计使得两个操作可以在不同的硬件单元上并行执行,充分体现了VPI的核心优势。
同步并执行立体声差异
在进行立体视差计算之前,需要确保两幅图像都已准备就绪。我们调用streamLeft.sync()来阻塞主线程,直到左图像的转换完成。然后可以将vpi.stereodisp 操作提交给streamRight。
# 同步streamLeft,确保左图准备就绪streamLeft.sync() # 在streamRightdisparityS16上提交立体视差操作=vpi.stereodisp(left, right, backend=vpi.Backend.OFA|vpi.Backend.PVA|vpi.Backend.VIC, stream=streamRight)
立体视差算法在VPI 后端(OFA、PVA、VIC)组合上运行,以充分利用专用硬件,最终生成S16 格式的差异图,表示两个图像中相应像素之间的水平偏移。
后处理和可视化
当对原始差异图进行后处理以进行可视化时,以Q10.5 定点格式表示的差异值将缩放到0-255 范围并保存。
# 后处理视差图# 将Q10.5 转换为U8 并进行可视化缩放disparityU8=disparityS16.convert(vpi.Format.U8,scale=255.0/(32*128),stream=streamRight,backend=vpi.Backend.CUDA) #在cpu 中可访问disparityU8=disparityU8.cpu() #用pillowd_pil=保存Image.fromarray(disparityU8)d_pil.save('./disparity.png')
最后一步是将原始数据转换为人类可读的图像,其中灰度值代表深度信息。
使用C++ API 的多流比较工作流程
先进的机器人技术依赖于高吞吐量,VPI 通过并行多流传输实现这一点。通过简单API 和硬件加速器的有效组合,VPI 使开发人员能够构建快速可靠的视觉处理流程——,类似于波士顿动力新一代机器人系统的流程。
VPI 使用VPIStream 对象。这些对象作为先进先出(FIFO)命令队列,可以异步向后端提交任务,从而实现在不同硬件单元上的并行操作执行(异步流)。
对于追求极致性能的关键任务应用程序,VPI 的C++ API 是理想的选择。
以下代码片段源自C++基准测试,用于演示多流立体视差工作流程的构建和执行过程。本示例通过SimpleMultiStreamBenchmarkC++应用程序实现:首先,预先生成合成的NV12_BL格式图像,以消除运行时生成数据带来的开销;然后并行处理多个数据流,并测量每秒帧数(FPS)以评估吞吐量性能。此外,该工具还支持保存输入图像以及差异图和置信图,以便于调试分析。通过预生成数据,该示例可以有效模拟高速实时工作负载场景。
资源配置、对象声明和初始化
我们首先声明并初始化执行管道所需的VPI 中的所有对象,包括创建流、输入/输出图像和立体视觉处理所需的有效负载。由于立体算法的输入图像格式为NV12_BL,因此我们将其与Y8_Er图像类型一起设置为中间格式转换的格式。
int TotalIterations=itersPerStream * numStreams;std:向量leftInputs(numStreams), rightInputs(numStreams),confidences(numStreams), leftTmps(numStreams), rightTmps(numStreams);std:向量leftOuts(numStreams), rightOuts(numStreams),差异(numStreams);std:向量stereoPayloads(numStreams);std:向量streamsLeft(numStreams),streamsRight(numStreams);std:向量事件(numStreams);int宽度=cvImageLeft.cols;int高度=cvImageLeft.rows;int vic_pva_ofa=VPI_BACKEND_VIC | VPI_BACKEND_OFA | VPI_BACKEND_PVA;VPIStereoDisparityEstimatorCreationParamsstereoPayloadParams;VPIStereoDisparityEstimatorParams stereoParams;CHECK_STATUS(vpiInitStereoDisparityEstimatorCreationParams(stereoPayloadParams));CHECK_STATUS(vpiInitStereoDisparityEstimatorParams(stereoParams));stereoPayloadParams.maxDisparity=128;stereoParams.maxDisparity=128;stereoParams.confidenceType=VPI_STEREO_CONFIDENCE_RELATIVE; for (int i=0; i numStreams; i++){ CHECK_STATUS(vpiImageCreateWrapperOpenCVMat(cvImageLeft, 0, leftInputs[i])); CHECK_STATUS(vpiImageCreateWrapperOpenCVMat(cvImageRight, 0, rightInputs[i]));检查状态(vpiStreamCreate(0,streamsLeft [i]));检查状态(vpiStreamCreate(0,streamsRight [i])); CHECK_STATUS(vpiImageCreate(宽度, 高度, VPI_IMAGE_FORMAT_Y8_ER, 0, leftTmps[i])); CHECK_STATUS(vpiImageCreate(宽度, 高度, VPI_IMAGE_FORMAT_NV12_BL, 0, leftOuts[i])); CHECK_STATUS(vpiImageCreate(宽度, 高度, VPI_IMAGE_FORMAT_Y8_ER, 0, rightTmps[i])); CHECK_STATUS(vpiImageCreate(宽度, 高度, VPI_IMAGE_FORMAT_NV12_BL, 0, rightOuts[i])); CHECK_STATUS(vpiCreateStereoDisparityEstimator(vic_pva_ofa,宽度,高度,VPI_IMAGE_FORMAT_NV12_BL,stereoPayloadParams,stereoPayloads [i])); CHECK_STATUS(vpiEventCreate(0, events[i]));}int outCount=saveOutput ? (numStreams * itersPerStream) : numStreams;disparities.resize(outCount);confidences.resize(outCount);for (int i=0; i outCount; i++){ CHECK_STATUS(vpiImageCreate(宽度, 高度, VPI_IMAGE_FORMAT_S16, 0, disparities[i])); CHECK_STATUS(vpiImageCreate(宽度, 高度, VPI_IMAGE_FORMAT_U16, 0, 置信度[i]));}
转换图像格式
我们使用VPI的C API为每个流提交图像转换操作,将来自相机的NV12_BL输入模拟帧转换为格式。
for (int i=0; i numStreams; i++){ CHECK_STATUS(vpiSubmitConvertImageFormat(streamsLeft[i], VPI_BACKEND_CPU, leftInputs[i], leftTmps[i], NULL)); CHECK_STATUS(vpiSubmitConvertImageFormat(streamsLeft[i], VPI_BACKEND_VIC, leftTmps[i], leftOuts[i], NULL)); CHECK_STATUS(vpiEventRecord(事件[i],streamsLeft[i])); CHECK_STATUS(vpiSubmitConvertImageFormat(streamsRight[i], VPI_BACKEND_CPU, rightInputs[i], rightTmps[i], NULL)); CHECK_STATUS(vpiSubmitConvertImageFormat(streamsRight[i], VPI_BACKEND_VIC, rightTmps[i], rightOuts[i], NULL)); CHECK_STATUS(vpiStreamWaitEvent(streamsRight[i], events[i]));}for (int i=0; i numStreams; i++){ CHECK_STATUS(vpiStreamSync(streamsLeft[i])); CHECK_STATUS(vpiStreamSync(streamsRight[i]));}
我们将操作提交到不同硬件上的两个单独的流,并从输入/输出图像的类型推断出特定类型。这次,我们还将在左流完成转换操作后记录一个VPIEvent。 VPIEvent是一个VPI对象,在流录制期间可以等待另一个流完成所有操作。这样我们就可以让右流等待左流的转换操作完成,而不阻塞调用线程(即主线程),从而实现多个左流和右流的并行执行。
同步并执行立体声差异
我们通过VPI的C API提交立体匹配计算任务,并使用std:chrono对其性能进行基准测试。
auto benchmarkStart=std:chrono:high_resolution_clock:now();for (int iter=0; iter itersPerStream; iter++){ for (int i=0; i numStreams; i++) { int dispIdx=saveOutput ? (i * itersPerStream + iter) : i; CHECK_STATUS(vpiSubmitStereoDisparityEstimator(streamsRight[i]、vic_pva_ofa、stereoPayloads[i]、leftOuts[i]、rightOuts[i]、视差[dispIdx]、confidences[dispIdx]、stereoParams)); }}//====================//结束基准测试for (int i=0; i numStreams; i++){ CHECK_STATUS(vpiStreamSync(streamsRight[i]));}auto benchmarkEnd=std:chrono:high_resolution_clock:now();
我们继续使用confidenceMap来提交计算任务并生成结果差异图。同时,停止基准计时器并记录转换和产生差异所花费的时间。将任务提交到所有流后,显式同步每个流,以确保调用线程在提交过程中不会被阻塞。
后处理和清理
我们利用VPI 的C API 与OpenCV 的互操作性来后处理差异图并将其保存在循环的每次迭代中。您可以根据需要选择保留输出数据以供检查,然后在循环结束后清理相关对象。
//====================//保存输出
(saveOutput){ for (int i = 0; i < numStreams * itersPerStream; i++) { VPIImageData dispData, confData; cv::Mat cvDisparity, cvDisparityColor, cvConfidence, cvMask; CHECK_STATUS( vpiImageLockData(disparities[i], VPI_LOCK_READ, VPI_IMAGE_BUFFER_HOST_PITCH_LINEAR, &dispData)); vpiImageDataExportOpenCVMat(dispData, &cvDisparity); cvDisparity.convertTo(cvDisparity, CV_8UC1, 255.0 / (32 * stereoParams.maxDisparity), 0); applyColorMap(cvDisparity, cvDisparityColor, cv::COLORMAP_JET); CHECK_STATUS(vpiImageUnlock(disparities[i])); std::ostringstream fpStream; fpStream << "stream_" << i / itersPerStream << "_iter_" << i % itersPerStream << "_disparity.png"; imwrite(fpStream.str(), cvDisparityColor); // Confidence output (U16 -> scale to 8-bit and save) CHECK_STATUS( vpiImageLockData(confidences[i], VPI_LOCK_READ, VPI_IMAGE_BUFFER_HOST_PITCH_LINEAR, &confData)); vpiImageDataExportOpenCVMat(confData, &cvConfidence); cvConfidence.convertTo(cvConfidence, CV_8UC1, 255.0 / 65535.0, 0); CHECK_STATUS(vpiImageUnlock(confidences[i])); std::ostringstream fpStreamConf; fpStreamConf << "stream_" << i / itersPerStream << "_iter_" << i % itersPerStream << "_confidence.png"; imwrite(fpStreamConf.str(), cvConfidence); }} // ====================// Clean Up VPI Objectsfor (int i = 0; i < numStreams; i++){ CHECK_STATUS(vpiStreamSync(streamsLeft[i])); CHECK_STATUS(vpiStreamSync(streamsRight[i])); vpiStreamDestroy(streamsLeft[i]); vpiStreamDestroy(streamsRight[i]); vpiImageDestroy(rightInputs[i]); vpiImageDestroy(leftInputs[i]); vpiImageDestroy(leftTmps[i]); vpiImageDestroy(leftOuts[i]); vpiImageDestroy(rightTmps[i]); vpiImageDestroy(rightOuts[i]); vpiPayloadDestroy(stereoPayloads[i]); vpiEventDestroy(events[i]);}// Destroy all disparity and confidence imagesfor (int i = 0; i < (int)disparities.size(); i++){ vpiImageDestroy(disparities[i]);}for (int i = 0; i < (int)confidences.size(); i++){ vpiImageDestroy(confidences[i]);} 收集基准测试结果 我们现在能够收集并展示基准测试的结果。 double totalTimeSeconds = totalTime / 1000000.0;double avgTimePerFrame = totalTimeSeconds / totalIterations;double throughputFPS= totalIterations / totalTimeSeconds; std::cout << "\n" << std::string(70, '=') << std::endl;std::cout << "SIMPLE MULTI-STREAM RESULTS" << std::endl;std::cout << std::string(70, '=') << std::endl;std::cout << "Input: RGB8 -> Y8_BL_ER" << std::endl;std::cout << "Total time: " << totalTimeSeconds << " seconds" << std::endl;std::cout << "Avg time per frame: " << (avgTimePerFrame * 1000) << " ms" << std::endl;std::cout << "THROUGHPUT: " << throughputFPS << " FPS" << std::endl;std::cout << std::string(70, '=') << std::endl; std::cout << "THROUGHPUT: " << throughputFPS << " FPS" << std::endl;std::cout << std::string(70, '=') << std::endl; 查看结果 在图像分辨率为960 × 600、最大视差为128的条件下,该方案在Thor T5000上以30 FPS的帧率运行立体视差估计,同时支持8个并行数据流(包括置信度图),且无需占用GPU资源。在MAX_N功耗模式下,其性能相比Orin AGX 64 GB提升至10倍。具体性能数据如表1所示。 立体视差全工作流(相对模式,分辨率:960 × 600,最大差异:128)的帧率(FPS)加速比随流数量变化情况:Orin AGX(64 GB)、Jetson Thor、T5000分别达到122、122.5、212、111.9、54.6、58.9、78.3、299.7。帧率(FPS)加速比流数量Orin AGX(64 GB)Jetson Thor T50001221225.52121119.546589.783299.7表1:Orin AGX与Thor T5000在RELATIVE模式下,立体视差处理流程的对比 波士顿动力如何使用VPI 作为Jetson平台的深度用户,波士顿动力借助视觉编程接口(VPI)来加速其感知系统的处理流程。 VPI支持无缝访问Jetson的专用硬件加速器,提供一系列优化的视觉算法(如AprilTags和SGM立体匹配),以及ORB、Harris Corner、Pyramidal LK等特征检测器,和由OFA加速的光流计算。这些技术构成了波士顿动力感知系统的核心,可通过负载均衡同时支撑原型验证与系统优化。通过采用VPI,工程师能够快速适配硬件更新,显著缩短从开发到实现价值的周期。 要点总结 Jetson Thor平台以及VPI等库在硬件功能上的进步,使开发者能够为边缘端机器人设计出高效且低延迟的解决方案。 通过充分发挥Jetson平台上各款可用加速器的独特优势,像波士顿动力这样的机器人公司能够实现高效且可扩展的复杂视觉处理,从而推动智能自主机器人在多种现实应用场景中的落地与发展。 关于作者 Chintan Intwala 是 NVIDIA 核心计算机视觉产品管理团队的成员,专注于构建 AI 赋能的云技术,为各行各业的大型计算机视觉开发者提供支持。在加入 NVIDIA 之前,Chintan 曾在 Adobe 工作,专注于构建 AI/ML 和 AR/Camera 产品及功能。他拥有麻省理工学院斯隆分校 (MIT Sloan) 的 MBA 学位,并已获得超过 25 项美国专利。 Jonas Toelke 是 NVIDIA 核心计算机视觉团队的一员,领导的团队专注于构建经过优化的计算机视觉产品,为各行各业的 TegraSoC 提供支持。加入 NVIDIA 之前,Jonas 曾就职于 Halliburton,专注于构建 AI/ ML 应用以解决石油物理问题。他拥有慕尼黑理工大学工程学博士学位,并已获得 20 项专利。 Colin Tracey 是 NVIDIA 的高级系统软件工程师。他在 Jetson 和 DRIVE 平台的嵌入式计算机视觉库和 SDK 上工作。 Arjun Verma 是 NVIDIA 的系统软件工程师,也是 NVIDIA 嵌入式设备计算机视觉产品的核心开发者。Arjun 最近刚从佐治亚理工学院获得机器学习硕士学位。